






- Автор: Alexander Babaev Igrolain джерело: RSDN Magazine # 1-2005
- Стандартні методи фільтрації рядків
- фільтрація рядків
- Структура бібліотеки JFilter
- опис
- застосування
- Правила, що входять в поставку
- Порівняння роботи різних типів обробки рядків
- висновок
- література
Автор: Alexander Babaev
Igrolain
джерело: RSDN Magazine # 1-2005
Опубліковано: 22.05.2005
Виправлено: 14.09.2005
Версія тексту: 1.0
Необхідність фільтрації рядків
Наша взаимовыгодная связь https://banwar.org/
Рядки використовуються дуже часто. А може бути застосовано до Інтернет-програмування можна сказати, що рядки використовуються постійно. Будь-яка відповідь сервера - це рядок, запит клієнта - теж рядок. Робота з XML-файлами - це знову робота з рядками, нехай і дуже формалізована. Тому необхідно вміти швидко і ефективно обробляти рядкові дані. Основна операція, яка використовується - це конкатенація (злиття). Вона реалізована для всього, чого завгодно і зазвичай дуже прозора. Друга ж операція - це зміна рядків. І тут думки щодо того, що використовувати, розходяться.
Стандартні методи фільтрації рядків
Для початку згадаємо, як відбувається робота з рядками в звичайній програмі. Використовується кілька методів. Перший можна назвати класичним. У цьому випадку для отримання результату використовуються стандартні операції пошуку, заміни, конкатенації і видалення частин рядка. Такий метод виправданий для швидкого вирішення найпростіших завдань, але як тільки потрібно реалізувати що-небудь більш-менш складне, миттєво починаються проблеми. Крім того, цей спосіб абсолютно не масштабується і дуже складно змінюється.
Другий метод - використання регулярних виразів (регекспов). Детально розглядати їх не має сенсу, є відмінна книга Дж. Фрідл [1], в якій все детально описано, в тому числі і може бути застосовано до Java. Переваги підходу полягають в тому, що регулярні вирази стандартизовані, мають величезними можливостями і дуже компактно записуються. Тобто якщо ви навчилися використовувати регулярні вирази в Perl або PHP, вам нічого не варто використовувати їх в Java (хоча все одно доводиться кожен раз з'ясовувати нюанси реалізації). Найголовніший недолік - складність, яка виростає з величезної потужності регулярних виразів. Прості регекспи може зрозуміти навіть початківець програміст, але більш-менш складні починаючому вже не по зубах. Регекспи ж, подібні представленому в лістингу 1, не зрозуміє ніхто навіть при дуже великому бажанні (в лістингу представлена приблизно восьма частина регулярного виразу, призначеного для перевірки коректності e-mail адреси і його відповідності RFC). Втім, є люди, які «читають» регулярні вирази «з листа». Даний приклад не зовсім показовий в тому сенсі, що і програма, що виконує аналогічну функцію, буде дуже і дуже складна. Але є і набагато простіші завдання, (приклади таких завдань будуть розглянуті нижче), в яких регулярні вирази використовувати так само незручно.
 Лістинг 1.Часть регулярного виразу, призначеного для перевірки коректності e-mail адреси, відповідності його RFC.
Лістинг 1.Часть регулярного виразу, призначеного для перевірки коректності e-mail адреси, відповідності його RFC. ^ [\ 040 \ t] * (?: \ ([^ \\\ x80- \ xff \ n \ 015 ()] * (?: (?: \\ [^ \ x80- \ xff] | \ ([ ^ \\\ x80- \ xff \ n \ 015 ()] * (?: \\ [^ \ x80- \ xff] [^ \\\ x80- \ xff \ n \ 015 ()] *) * \) ) [^ \\\ x80- \ xff \ n \ 015 ()] *) * \) [\ 040 \ t] *) * (?: (?: [^ (\ 040) <> @,;: " . \\\ [\] \ 000- \ 037 \ x80- \ xff] + (?! [^ (\ 040) <> @,;: ". \\\ [\] \ 000- \ 037 \ x80- \ xff]) | "[^ \\\ x80- \ xff \ n \ 015"] * (?: \\ [^ \ x80- \ xff] [^ \\\ x80- \ xff \ n \ 015 "] *) * ") [\ 040 \ t] * (?: \ ([^ \\\ x80- \ xff \ n \ 015 ()] * (?: (?: \\ [^ \ x80- \ xff] | \ ([^ \\\ x80- \ xff \ n \ 015 ()] * (?: \\ [^ \ x80- \ xff] [^ \\\ x80- ... ... ... ... ... \ xff]) | \ [(?: [^ \\\ x80- \ xff \ n \ 015 \ [\]] | \\ [^ \ x80- \ xff]) * \]) [\ 040 \ t] * (?: \ ([^ \\\ x80- \ xff \ n \ 015 ()] * (?: (?: \\ [^ \ x80- \ xff] | \ ([^ \\\ x80- \ xff \ n \ 015 ()] * (?: \\ [^ \ x80- \ xff] [^ \\\ x80- \ xff \ n \ 015 ()] *) * \)) [^ \\\ x80- \ xff \ n \ 015 ()] *) * \) [\ 040 \ t] *) *) *>) $
Інший важливий недолік регулярних виразів полягає в тому, що мало хто розуміє, як вони працюють. «Я пишу це, він робить те ...» А як - це проблема тих, хто бібліотеку розробляє. «Чукча не читач, чукча письменник». В результаті - ляпи, незрозумілі «глюки», і неправильно, некоректно працюючий програмний код. Найчастіше регекспи ненастраіваеми. Щоб змінити регулярний вираз, часто доводиться змінювати код і перекомпіліровать його. Не можна просто поміняти значення однієї змінної для того, щоб трохи змінити логіку роботи.
фільтрація рядків
Після досить тривалого використання різного роду методів обробки рядків з'явилося бажання поєднати настраиваемость звичайного класу і потужність регулярних виразів, а в якості бази для цього використовувати автомати [2-4]. Розглянемо такий підхід на конкретному прикладі. Нехай необхідно обробляти рядки записів в інтернет-форумі. При цьому потрібно реалізувати обробку наступних правил:
- Всі слова довше деякої кількості символів N розбивати пробілами на відрізки, довжина яких менше, або дорівнює N.
- Якщо довжина повідомлення більше M, то залишати тільки перші M символів.
- Замінювати три точки символом крапки.
- Замінювати два поспіль символу «мінус», обрамлених пробілами, символом «тире».
- Замінювати символи «" »правильними лапками в російській тексті -« ялинками »і« лапками ».
- Замінювати посилання на інтернет-ресурси (http: // ..., ftp: // ...) HTML-посиланнями.
- Замінювати e-mail адреси HTML-посиланнями. При цьому адресою для спрощення вважаємо послідовність непробельний символів, яка містить «@». Це не найкраще визначення, але працює досить часто.
- Замінювати комбінації символів, які позначають стандартні емотикони (смайли), відповідними картинками.
- «Знешкоджувати код». Тобто робити так, щоб користувач не міг в тексті повідомлення ввести шкідливий HTML-код. Таким кодом традиційно вважається будь-який крім деяких дуже простих тегів <b>, <i>, <u> і аналогічних.
- За умови дотримання правила номер дев'ять, дати користувачеві можливість форматування тексту, а саме, виділення тексту напівжирним, похилим шрифтом, перекреслення або підкреслення тексту, виділення цитати і тексту фіксованої (коду програми, наприклад).
Ці правила досить стандартні для практично будь-якої системи, де використовується робота з текстом. Існує безліч варіантів їх реалізації. Найпоширеніший - за допомогою вже згадуваних регулярних виразів [5]. При цьому будується по одному або кілька виразів на кожне правило, після чого вони в певному порядку застосовуються до рядка. Виконання кожного регулярного виразу - це один прохід по рядку, отже, таких прогонів буде величезна кількість. Правда, велика частина з них буде порожній, але навіть вони займають якийсь час.
Безумовно, можна написати таке регулярний вираз, яке буде виконувати всі правила відразу, але, боюся, що його написання займе не один день, а найменша зміна зажадає дуже серйозних зусиль.
Можливий інший варіант, який і підводить безпосередньо до автоматного методу роботи. Ті, хто більш глибоко цікавився регулярними виразами, скажуть, що автомати і регекспи - це одне і те ж. Так, будь-який регулярний вираз - це всього лише коротка строкова запис автомата. Але обговорення такого роду відмінностей виходить далеко за рамки статті.
Код, що обробляє рядок, називається фільтром. Фільтр посимвольний перебирає рядок, і для кожного символу перевіряє, чи є обробник цього символу. Якщо є - то передає управління йому. Інакше просто додає символ у вихідний потік і переходить до наступного.
На малюнку 1 представлений граф станів автомата, який керує роботою фільтра.
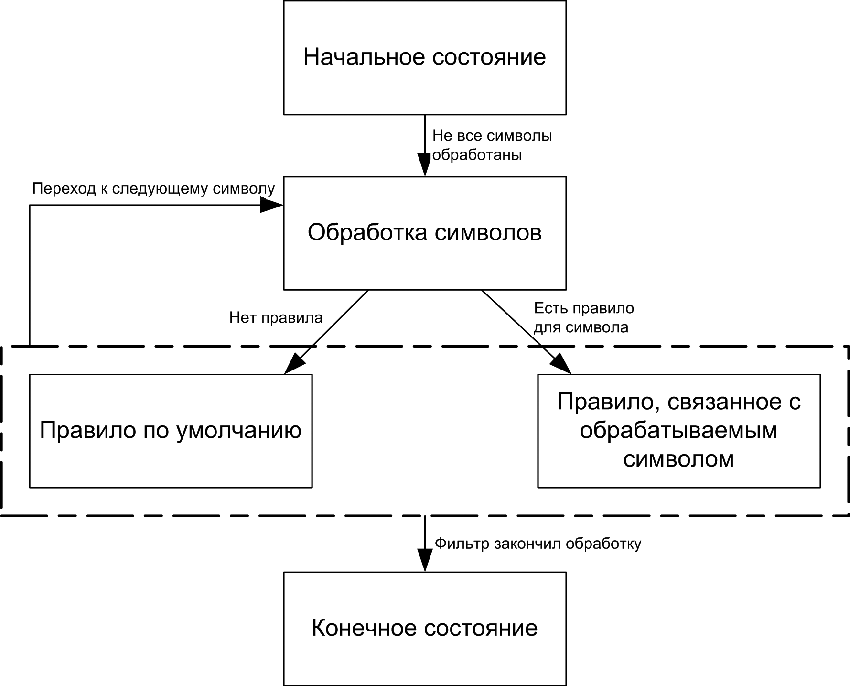
Малюнок 1. Граф станів автомата, який керує роботою фільтра.
Лістинг 2 показує, як ця логіка реалізована в коді.
Лістинг 2. Реалізація автомата.
public String process (String aString) throws FilterException {initRules (); if (aString == null || aString.length () == 0) {return ""; } Source source = new Source (aString); Result result = new Result (); while (! result.getLastRuleResult (). equals (RuleResult.FILTER_FINISHED_PROCESSING)) {result.setLastRuleResult (RuleResult.CHAR_NOT_CHANGED); if (source.isStringFinished ()) {break; } Try {source.prepare (); } Catch (FilterException e) {e.printStackTrace (); if (e.getCanContinue (). equals (FilterException.CONTINUABLE)) {source.addToPosition (1); continue; } Else if (e.getCanContinue (). Equals (FilterException.FATAL)) {throw e; }} ProcessRules (source, result); if (result.getLastRuleResult (). equals (RuleResult.CHAR_NOT_CHANGED)) {EMPTY_RULE.process (source, result, this); } Else if (result.getLastRuleResult (). Equals (RuleResult.FILTER_FINISHED_PROCESSING)) {break; }} Result.appendEndAppendersInReverseOrder (); return result.getResult (); }
Тепер, коли зрозуміло, як працює основний цикл програми, подивимося на деякі правила. Наприклад, ось правило заміни трьох точок спеціальним символом (в лістингу 3 наведено тільки метод обробки символу, але не весь клас).
Лістинг 3. Реалізація правила заміни трьох точок на «& amp; hellip;» public class HellipRule extends AbstractRule {private static final char CHARACTER = '.'; private static final Character INITIATOR = new Character (CHARACTER); public Character getInitiatorCharacter () {return INITIATOR; } Public void process (Source aSource, Result aResult, IFilter aFilter) {// перевіряємо, що за поточної точкою будуть ще дві точки if (StringUtils.isSymbol (aSource.getSource (), aSource.getPosition () + 1, CHARACTER) && StringUtils.isSymbol (aSource.getSource (), aSource.getPosition () + 2, CHARACTER)) {aResult.append ( "& hellip;"); aResult.setLastRuleResult (RuleResult.CHAR_FINISHED_PROCESSING); aSource.addToPosition (3); }}}
У лістингу 4 представлено правило загальної обробки «подвійних символів». Це правило, яке є базою для безлічі правил форматування, що дозволяють виділяти текст «жирним», «похилим» і так далі, не вдаючись до тегам HTML, але обрамляючи потрібні шматки тексту в «зірочки», «похилі риси» та інші легко запам'ятовуються символи .
Лістинг 4. Реалізація правила обробки «подвійних символів». public void process (Source aSource, Result aResult, IFilter aFilter) {int nextPosition = aSource.getPosition () + 1; if (isSymbol (aSource.getSourceString (), nextPosition, getSymbol ())) {if (getState (). equals (DoubleCharacterState.STATE_OUT)) {setState (DoubleCharacterState.STATE_IN); aSource.addToPosition (2); aResult.append (getPrefix ()); aResult.addEndAppend (getPostfix ()); aResult.setLastRuleResult (RuleResult.CHAR_FINISHED_PROCESSING); } Else if (getState (). Equals (DoubleCharacterState.STATE_IN)) {if (aResult.containsEndAppend (getPostfix ())) {setState (DoubleCharacterState.STATE_OUT); aSource.addToPosition (2); aResult.append (getPostfix ()); aResult.removeEndAppend (getPostfix ()); aResult. setLastRuleResult (RuleResult.CHAR_FINISHED_PROCESSING); }}}}
Структура бібліотеки JFilter
класи
На малюнку 2 представлена діаграма класів бібліотеки, при цьому велика частина класів правил прибрана, щоб підвищити читаність.
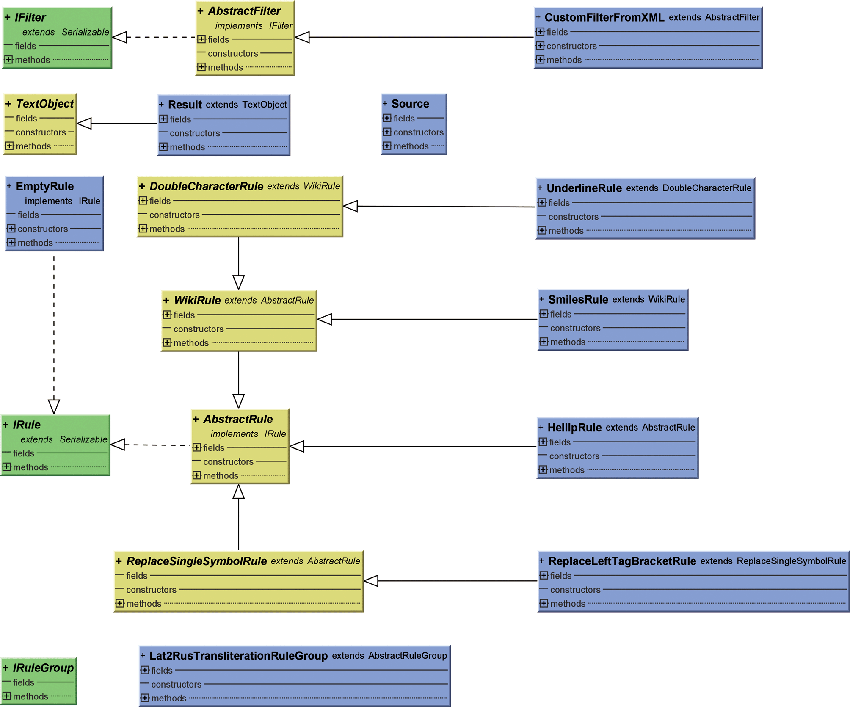
Малюнок 2. Діаграма класів.
опис
У бібліотеці JFilter є кілька інтерфейсів:
- IFilter (лістинг 5), який описує сам фільтр.
Лістинг 5. Інтерфейс фільтра public interface IFilter extends Serializable {public String process (String aSourceString) throws FilterException; public void disableRuleByClassName (Class aRuleClass); public void enableRuleByClassName (Class aRuleClass); public void enableAllRules (); public void disableAllRules (); void addRule (IRule aRule); }
- IRule (лістинг 6), що показує, які методи повинні бути у правила.
Лістинг 6. Інтерфейс правила. public interface IRule extends Serializable {public void initialize (); void setParameters (Map aParameters) throws FilterException; public void setEnabled (boolean aEnabled); public boolean isEnabled (); public Character getInitiatorCharacter (); public void process (Source aSource, Result aResult, IFilter aFilter); }
- IRuleGroup (лістинг 7) - інтерфейс роботи з групою однотипних правил, як, наприклад, правила транслітерації.
Лістинг 7. Інтерфейс групи правил. public interface IRuleGroup {public void addRules (IFilter aFilter); public void setEnabled (boolean aEnabled); public boolean isEnabled (IFilter aFilter); public void setParameters (Map aParameters); }
Для спрощення роботи з системою написано кілька класів, які допомагають при створенні нових фільтрів і правил. Такими класами є AbstractFilter і AbstractRule. Перший описує всі методи, необхідні для роботи стандартного фільтра. Тому для того, щоб створити потрібний фільтр, можна просто створити клас-спадкоємець AbstractFilter і в конструкторі викликати метод addRule (), додавши все необхідне в потрібній послідовності (лістинг 8).
Лістинг 8. Складання фільтра з окремих правил. public class WikiFilter extends AbstractFilter {public WikiFilter (int aMaxWordLength, int aMaxStringLength) {addRule (new ReplaceLeftTagBracketRule ()); addRule (new ReplaceAmpersandTagBracketRule ()); addRule (new EkranRule ()); addRule (new AnchoringRule (aMaxWordLength)); ... ... ... addRule (new BreakWordsRule (aMaxWordLength)); addRule (new MaxLengthRule (aMaxStringLength)); }}
Після цього обробка рядка даними фільтром являє собою тривіальну завдання:
String result = new WikiFilter (maxWordLength, maxStringLength) .process (sourceString);
AbstractRule визначає методи setEnabled () і isEnabled (), однакові для більшості фільтрів.
public abstract class AbstractRule implements IRule {private ThreadLocal _enabledThreadLocal = new ThreadLocal () {protected Object initialValue () {return Boolean.TRUE; }}; public void setParameters (Map aParameters) throws FilterException {} public void initialize () {} public void setEnabled (boolean aEnabled) {_enabledThreadLocal.set (Boolean.valueOf (aEnabled)); } Public boolean isEnabled () {return ((Boolean) _enabledThreadLocal.get ()). Equals (Boolean.TRUE); }}
Є можливість відключати деякі правила безпосередньо в процесі роботи фільтру або між виконаннями методу process (). Можна також динамічно змінювати фільтр або налаштовувати його. При цьому не потрібно перекомпіляції коду або самого фільтра.
Також створено допоміжний клас CustomFilterFromXML, який дозволяє завантажити конфігурацію фільтра з XML-файла і автоматично її оновлює при зміні XML-файла.
застосування
Метод фільтрації рядків, представлений в даній статті, можна застосувати не тільки в вузькоспеціалізованої області роботи з інтернет-текстами. Створюючи різні правила, легко створювати рядки, які будуть управляти, наприклад поведінкою програми. Можливості необмежені. Описана тут система називається JFilter і поширюється вільно, її сторінка в інтернеті: http://blog.existence.ru/exception/.products.JFilter . Там можна знайти як бібліотеку в форматі jar, так і вихідні тексти з документацією. У додатку наведено код інтерфейсів фільтра та правила, які є основними інтерфейсами системи. JFilter використовується в системі блогів JDnevnik [6] і ще в декількох проектах.
Правила, що входять в поставку
Всі стандартні правила написані в стилі, допускає одночасну обробку фільтром кількох рядків, завдяки чому їх можна використовувати в многопоточной середовищі.
Стандартні правила (jfilter.rules.general) BreakWorksRule - розбиває довгі слова пропуском. EkranRule - правило екранування спецсимволов. MaxLengthRule - правило, яке обмежує довжину рядків. HTML-правила (jfilter.rules.html) AnchoringRule - заміна тексту, що починається з http: // (або аналогів) та закінчується пропуском, HTML-посиланням. MailRule - заміна тексту, укладеного в прогалини і містить символ «@», HTML-посиланням. Емотікони (jfilter.rules.smiles) PreSmiler - заміна позначень емотикони ( «:-)», «;)» і так далі) на їх стандартні позначення для обробки SmilesRule'ом. SmilesRule - заміна одного слова, укладених в парні двокрапки «::», HTML-картинками. Транслітерація (jfilter.rules.transliteration) Lat2RusTransliterationRuleGroup - транслітерація. Відповідає ISO і ГОСТ (тобто можна писати як по ГОСТу, так і позначеннями ISO; поки конфліктів такого варіанту я не виявив). Типографіка (jfilter.rules.typografica) AbbreviationsRule - заміна (c), (p), (r), (tm) відповідними HTML-символи. HellipRule - заміна трьох точок поспіль символом «крапки». LongDashRule - Заміна символу «мінус», обрамленого пробілами символом «тире». QuotesRule - заміна «знака дюйма» коректними лапками для російської мови. Вікі-форматування (jfilter.rules.wacko) AnchorRule - створення посилань у вигляді ((link)). BlockquoteRule - цитата (>> текст >>). BoldRule - виділення напівжирним шрифтом (** напівжирний **). HeaderRule - заголовок (== заголовок ==). ItalicRule - виділення курсивом (// курсив //). MonospaceRule - виділення моноширінним шрифтом (## моно ##). NoteRule - виділення зауваження (span class = "note"). ParagraphRule - Робота з перекладами рядка (одиночний новий рядок - <br/>, два поспіль - <p>). PreformattedRule - виділення попередньо відформатованого тексту (%% вже форматрованний текст %%). ReplaceAmpersandTagBracketRule - заміна символу "&" відповідним HTML-аналогом (& amp;). ReplaceLeftTagBracketRule - заміна символу "<" відповідним HTML-аналогом (& lt;). SmallRule - виділення дрібним шрифтом (++ невеликий ++). StrikeRule - виділення перекресленням (--перечеркнутий--). SubscriptRule - виділення нижнім індексом (vvніжній індексvv). SuperscriptRule - виділення верхнім індексом (^^ верхній індекс ^^). UnderlineRule - виділення підкресленням (__подчерківаніе__). Таблиця 1. Стандартні правила.
Порівняння роботи різних типів обробки рядків
Властивість Класичний спосіб Регулярні вирази Фільтрація Простота реалізації Просто Дуже складно Складно Можливості зміни Для простих завдань - дуже великі, для складних - дуже складні Тільки разом з перекомпиляцией вираження Максимальні Простота використання Дуже просто Просто для тих, хто витратив багато часу на навчання Дуже просто Швидкість роботи швидко на простих варіантах, зазвичай повільно на складних, сильно залежить від реалізації швидко, якщо правильно використовувати швидко Таблиця 2. Порівняння різних типів обро ки рядків.
висновок
Хочеться відзначити, що бібліотека JFilter продовжує розвиватися, на даний момент реалізовано дуже багато, але далеко не все з того, що хотілося б реалізувати. У найближчому майбутньому передбачається написання додаткових правил для класичної, «паперової» типографіки, які допомагали б редакторам і верстальщикам самих звичайних, паперових книг / журналів / газет.
література
- Фрідл Дж., Mastering Regular Expressions. Питер, 2003 рік.
- http://is.ifmo.ru , Санкт-Петербурзький Державний університет інформаційних технологій, механіки і оптики, кафедра «Технології програмування».
- Бабаєв А., МИР ПК - ДИСК. 2003. №12, Транслітерація і як правильно її треба програмувати.
- http://is.ifmo.ru/projects/bone/ - створення скелетної анімації на основі автоматного програмування.
- http://wackowiki.com/projects/WackoFormatter -Бібліотека для форматування тексту WackoFormatter.
- http://blog.existence.ru/exception/.products.JDnevnik - Система блогів JDnevnik.
