






- Model 1: мішок слів
- Model 2: облік порядку слів у реченні
- Model 3: додавання відсутніх слів
- Model 4: перестановки слів
- Model 5: багфіксів
Наша взаимовыгодная связь https://banwar.org/
В середньому за день я відкриваю Google Translate в два рази частіше, ніж Facebook. Перекладаючи черговий цінник в супермаркеті, я вже не відчуваю тепле дихання кіберпанку - це буденна реальність. Але ж дослідники майже століття билися над алгоритмами машинного перекладу, половину з якого без особливих успіхів. Однак саме їх напрацювання тепер лежать в основі всіх сучасних систем обробки мови - від пошукачів до мікрохвильовок з голосовим управлінням. Сьогодні поговоримо як розвивався і як влаштований онлайн-переклад. 
Машина Троянського (Ілюстрація з описів. Фоток, природно, не збереглося)
Наша історія починається в 1933 році. Радянський вчений Петро Троянський звертається до Академії Наук СРСР з винайденої їм «машиною для підбору і друкування слів при перекладі з однієї мови на іншу». Машина була вкрай проста: великий стіл, друкарська машинка зі стрічкою і плівковий фотоапарат. На столі лежали картки зі словами та їх перекладами на чотирьох мовах.
Оператор брав перше слово з тексту, знаходив з ним картку, фотографував її, а на друкарській машинці набирав його морфологічну інформацію - «іменник, множина, родовий відмінок». Її клавіші були модифіковані для зручності, кожна однозначно кодувала одна з властивостей. Стрічка друкарської машинки і плівка камери подавалися паралельно, на виході формуючи набір кадрів зі словами і їх морфологією:
Отримана стрічка віддавалася знають конкретні мови лінгвістам, які перетворювали набір фотографій в зв'язний літературний текст. Виходить, щоб перекладати тексти як оператору, так і лінгвістам потрібно знати тільки свою рідну мову. Машина Троянського вперше на практиці реалізувала той самий «проміжний мову» (interlingua), про створення якого мріяли ще Лейбніц і Декарт.
За класикою в СРСР винахід визнали «непотрібним», Троянський помер від стенокардії, 20 років намагаючись її доопрацювати. Ніхто в світі так і не знав про машину, поки його патенти не відкопали в ахівах два інших радянських вчених в 1956 році. Сталося це не випадково.
Вони шукали відповідь на виклик холодної війни, адже 7 січня 1954 року в штаб-квартирі IBM в Нью-Йорку відбувається Джорджтаунський експеримент . Комп'ютер IBM 701 вперше в світі автоматично перевів 60 пропозицій з російської мови на англійську. «Дівчина, яка не розуміє ні слова на мові Рад, набрала російські повідомлення на перфокартах. Машинний мозок зробив їх англійський переклад і видав його на автоматичний принтер з шаленою швидкістю - дві з половиною рядки в секунду », - повідомлялося в прес-релізі компанії IBM.

IBM 701
Газети рясніли радісними заголовками, але ніхто не говорив, що приклади для перекладу були ретельно підібрані і відтестували, щоб виключити будь-яку неоднозначність. Для повсякденного використання ця система підходила чи не краще кишенькового розмовника. Але гонка озброєнь була запущена. Канада, Німеччина, Франція і особливо Японія теж підключилися до гонки за машинний переклад.
Сорок років вчені билися в спробах поліпшити машинний переклад, але марно. У 1966 американський комітет ALPAC публікує свій знаменитий звіт, в якому називає машинний переклад дорогим, неточним і безперспективним. Звіт рекомендує більше сфокусуватися на розробці словників, ніж на машинному перекладі, через що иследователи з США практично на десятиліття вибувають з гонки.
Незважаючи на все, саме спроби вчених, їх дослідження і напрацювання згодом ляжуть в основу всього сучасного Natural Language Processing. Пошуковики, спам-фільтри, персональні асистенти - все це з'явиться завдяки тому, що купка країн сорок років поспіль намагалася шпигувати один за одним.
Наводжу англійські назви бо саме ці абревіатури повсюдно використовуються в текстах і розмовах. Як HTTP або RSA, наприклад.
Ідеї машинного перекладу на основі правил почали з'являтися ще в 1970-х роках. Вчені підглядали за роботою лінгвістів-перекладачів і намагалися запрограмувати свої великі і повільні компуктери повторювати за ними. Їх системи складалися з:
- Двомовного словника (EN -> RU)
- Набору лінгвістичних правил під кожна мова (іменники жіночого роду закінчуються на -а / -я)
В общем-то все. За бажанням вони доповнювалися Хакамі типу списків імен, коректорами орфографії і транслітератор.
ПРОМТ і Systran - найвідоміші приклади RBMT-систем. «Охолодіть траханье, вуглепластик, я розглядаю її користь», - золотий час же. Аліекспресс он до сих пір так переводить.
Але навіть у них були свої нюанси і підвиди.
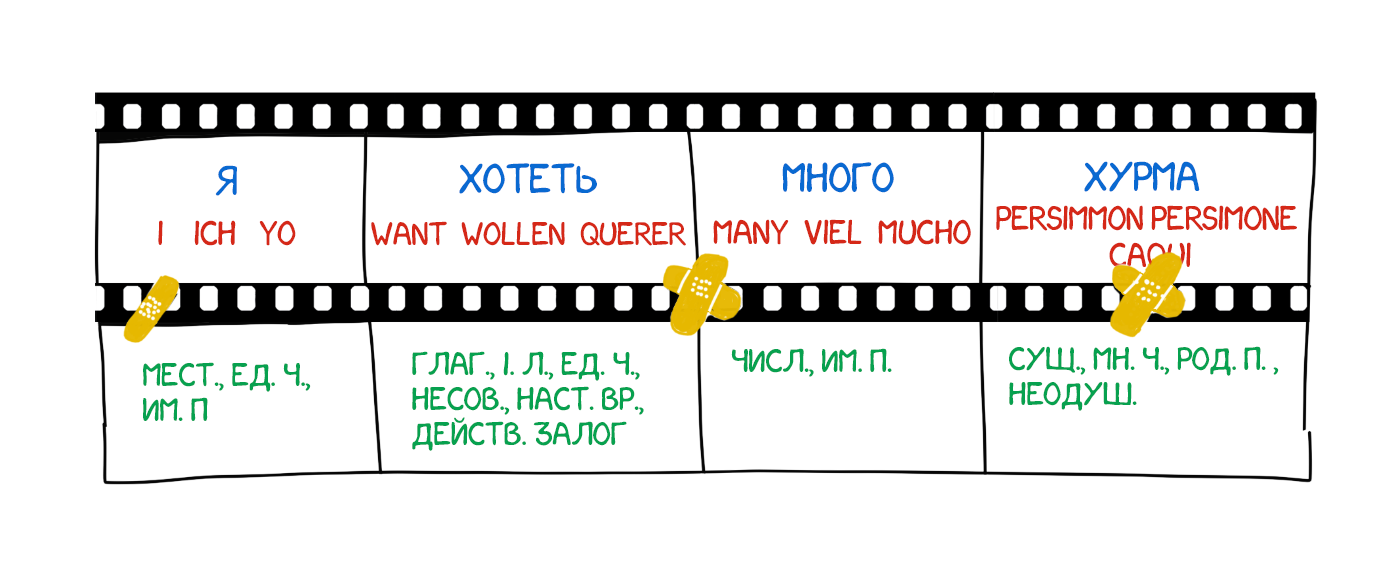
Найпростіший спосіб машинного перекладу, зрозумілий будь-якому п'ятикласникові. Ділимо текст за словами, переводимо кожне, трошки правимо морфологію, щоб звучало не кривлячи, узгодимо відмінки, закінчення і решті синтаксис. Спеціально навчені лінгвісти ночами пишуть правила під кожне слово.
На виході отримуємо щось перекладене. Найчастіше повне гівно. Тільки лінгвістів даремно попсували.
У сучасних системах підхід не використовується взагалі, розповідаю чисто поржать.
У них ми не кидаємося відразу переводити за словником, а трохи готуємося. Розбираємо текст на підмет і присудок, шукаємо визначення і все інше як вчили в школі. Дорослі дядьки говорять «виділяємо синтаксичні конструкції». Після цього в систему ми вже не закладаємо правила перекладу кожного слова, а маніпулюємо цілими конструкціями. У теорії навіть можемо домогтися більш-менш непоганий конвертації порядку слів у мовах.
На практиці все ще важко, лінгвісти, як і раніше гинуть від фізичного виснаження, а переклад виходить фактично дослівний. З одного боку простіше: можна задати загальні правила узгодження за родом і падежу. З іншого складніше: поєднань слів набагато більше, ніж самих слів. Кожен варіант не врахуєш руками.
Повністю конвертуємо вихідне пропозицію в якесь проміжне представлення, єдине для всіх мов світу (interlingua). В ту саму інтерлінгва, якій марив сам Декарт. Спеціальний метамова, правила якого єдині і покривають всі мови світу, тим самим перетворюючи переклад в технічне завдання перегону туди-сюди. Спеціальні парсери потім конвертують цю інтерлінгва в потрібну мову і ось вона сингулярність.
Часто інтерлінгва плутають з трансферними системами, адже там теж є конвертація. Однак в трансферних системах правила конвертації пишуться під два конкретних мови, а в інтерлінгвістіческом між кожним мовою і інтерлінгва. Додавши в інтерлінгвістіческом систему третю мову, ми зможемо переводити між усіма трьома, а в трансферній немає.
У реальному житті все виявилося не так солодко. Створити універсальну інтерлінгва вручну виявилося вкрай складно. Деякі вчені життя свої поклали на це. Нічого не вийшло, однак завдяки їм у нас з'явилися методи морфологічного, синтаксичного і навіть іноді семантичного аналізу. одна тільки модель Сенс <-> Текст чого вартий.
Але сама ідея проміжного мови ще повернеться до нас пізніше. Треба буде лише 30 років почекати.
Як можна помітити, всі RBMT тупі, жахливі, тому зараз рідко використовуються. Хіба що в специфічних місцях типу перекладу метеозведень. Серед плюсів RBMT відзначають морфологічну точність (чи не плутає слова), відтворюваність (всі перекладачі отримають однаковий результат) і можливість затюніть під предметну область (навчити спеціальним термінам економістів або програмістів).
Навіть якщо уявити, що вченим і вдалося б створити ідеальну RBMT, а лінгвістам закласти в неї все правила правопису, за дверима їх вже чекало веселощі - виключення. Неправильні дієслова в англійській, плаваючі приставки в німецькому, суфікси в російській, так і просто ситуації, коли «у нас так не говорять, треба ось так». Спроба врахувати всі нюанси обертається мільйонами витрачених даремно человекочасов.
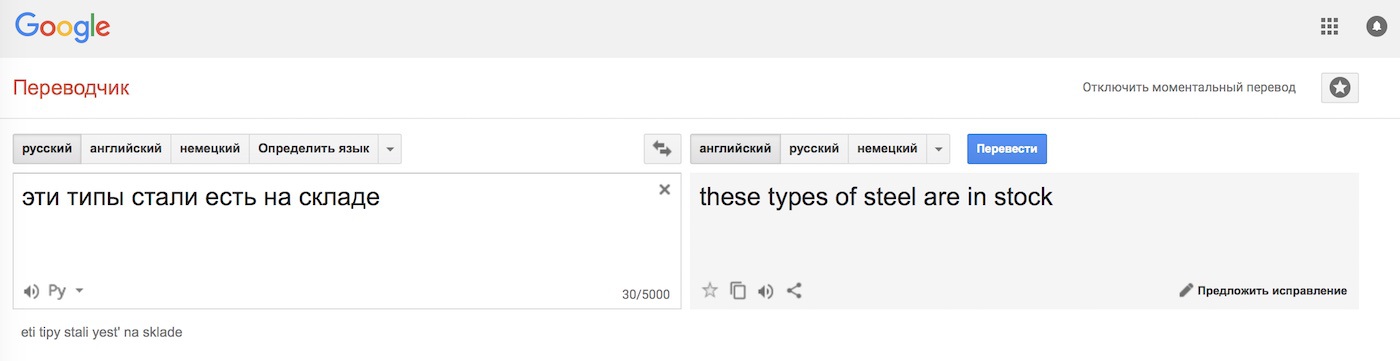
Купа правил все одно не вирішує головної проблеми - омонімія. Одне і те ж слово може мати різне значення залежно від контексту, а значить відрізняється і його переклад. Пригадується приклад з однієї зі старих лекцій Сегаловіча: «Ці типи стали є на складі». Він говорив, що може знайти чотири різних варіанти прочитання цієї пропозиції. А ви?
Наші мови розвивалися аж ніяк не на основі граматик і правил, про які люблять розмірковувати лінгвісти. Вони більше залежать від того, хто на кого напав і завоював за останні триста років. Ось як мені тепер навчити цьому машину?
За сорок років холодної війни вчені так і не змогли знайти виразного рішення. RBMT здох.
У битві за машинний переклад в ті роки була особливо зацікавлена Японія. Там не було холодної війни, але були свої причини: вкрай мало хто в країні знав англійську. Це обіцяло великі труднощі на вечірці наступаючої глобалізації, через що японці були вкрай мотивовані знайти робочий метод машинного перекладу.
Англо-японський переклад на основі одних тільки правил вкрай складний, будова мов відрізняється, майже всі слова доводиться переставляти і додавати нові. У 1984 році вченому університету Кіото на ім'я Макото Нагао приходить ідея. А що якщо не намагатися кожного разу переводити заново, а використовувати вже готові фрази?
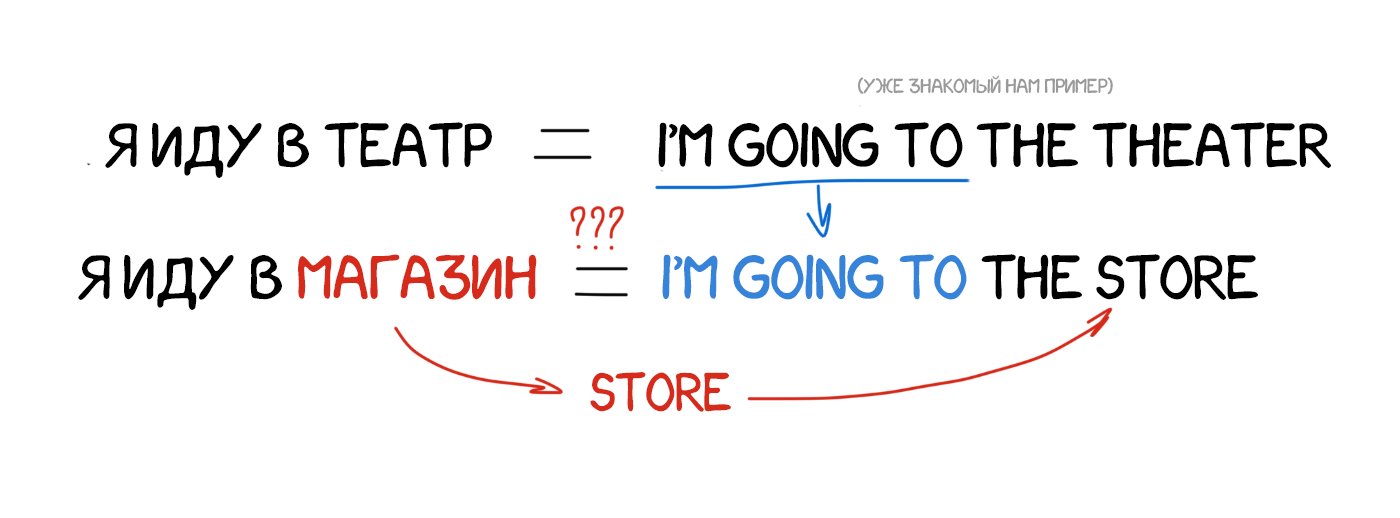
Припустимо нам треба перевести пропозицію «я йду в магазин». Десь в заначці у нас вже є переклад схожою фрази «я йду в театр» і словник з перекладом слова «магазин». Адже ми можемо якось спробувати обчислити різницю і перевести тільки одне слово в наявному прикладі, що не похер інші конструкції. І чим більше у нас прикладів - тим краще переклад.
Я ж теж так строю фрази чужою мовою!
Історична важливість методу була в тому, що вчені всього світу вперше прозріли: можна не витрачати роки на створення правил і винятків, а просто взяти купу вже наявних перекладів і згодувати їх машині. Це була ще не революція, але крок туди. До революції і винаходи статистичного перекладу залишалося п'ять років.
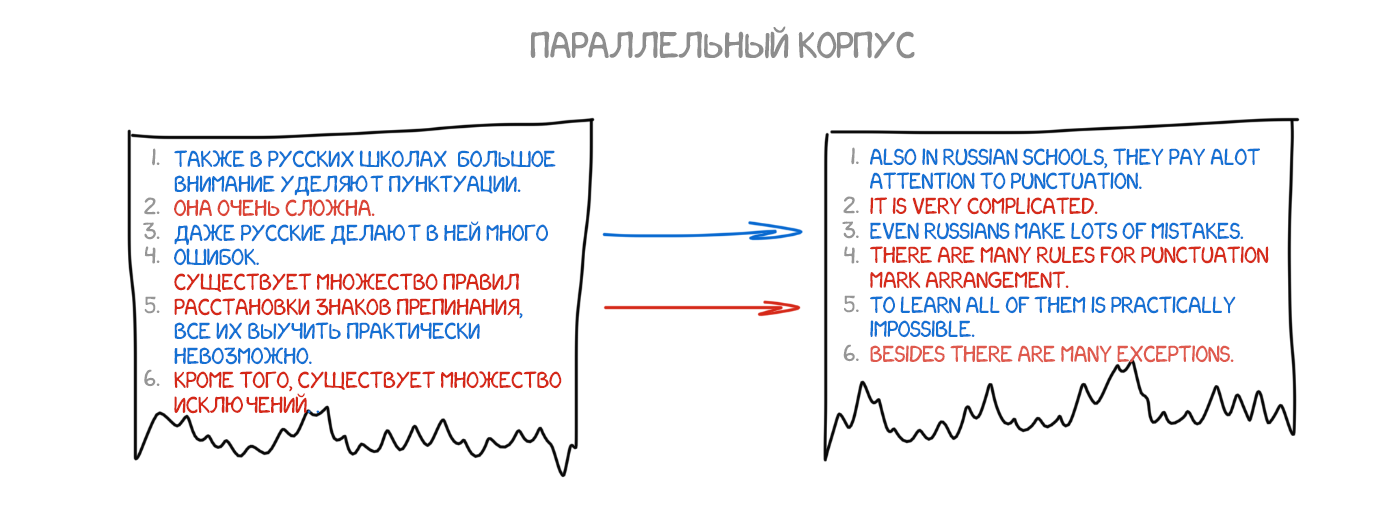
На рубежі 1990 року в дослідницькому центрі IBM вперше показали систему машинного перекладу, яка нічого не знала про правила і лінгвістиці. Вчені показали бездушному комп'ютера дуже багато однакових текстів на двох мовах, і змусили його розбиратися в закономірностях самому.
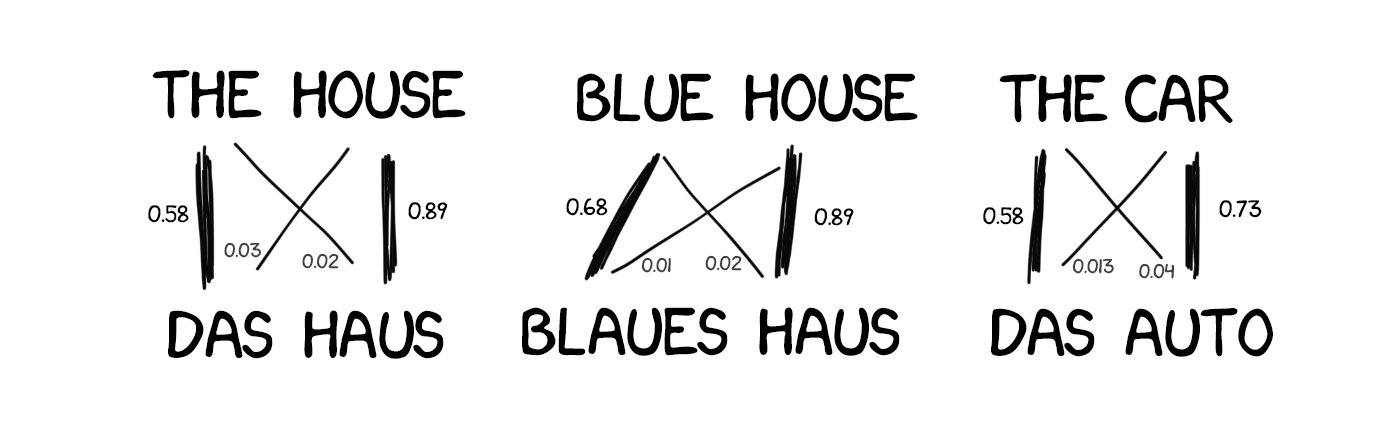
Ідея була проста і одночасно красива: беремо одну пропозицію на двох мовах, розбиваємо його за словами і намагаємося зіставити кожне слово з його з перекладом. Повторюємо цю операцію десь 500 млн раз, а машина вважає скільки разів у нас слово das Haus переводилося як house, building, construction, ітд. Напевно найчастіше це був house, його і будемо використовувати. Зауважте, ми не задали ні правил, ні словників. Машина сама все знайшла, керуючись чистою статистикою і логікою «люди переводять ось так, значить і я буду». Так народився статистичний переклад.
Точність таких перекладачів виявилася помітно вище всіх попередніх, а розробка не вимагала ніяких лінгвістів. Знаходимо більше текстів - покращуємо переклад.
Одна проблема: як машина здогадається, що для das Haus парою є саме house, а не будь-яке інше слово з пропозиції? Порядок слів-то різний, звідки ми знаємо як саме треба розбити і знайти потрібні слова?
Кишки статистичного перекладу в Google Translate. Гугл не тільки показує ймовірності, але і вважає зворотний статистику.
Відповідь: ніяк. На початку роботи машина з рівною часткою ймовірності вважає, що слово das Haus перекладається як кожне зі слів наявної пропозиції. Коли вона зустрічає das Haus в інших пропозиціях, то кількість перекладів das Haus як house починає збільшуватися з кожним разом. Це називається «алгоритмом вирівнювання слів» (word aligment). Типова задача машинного навчання, такі вирішують в універах.
Машині потрібні мільйони і мільйони пропозицій на двох мовах, щоб набрати статистику по кожному слову. І де стільки взяти? Так он, в Європарламенті і раді ООН ведуть конспекти засідань на мовах усіх країн-членів, їх і візьмемо. Зараз вони навіть відкрили для скачування: UN Corpora і Europarl Corpora .
Перші системи статистичного перекладу знову почали з розподілу по словам. Це здавалося логічно і просто. Першу винайдену модель статистичного перекладу в IBM назвали IBM Model 1. Витончено, так. Здогадайтеся як назвали другу?
Model 1: мішок слів
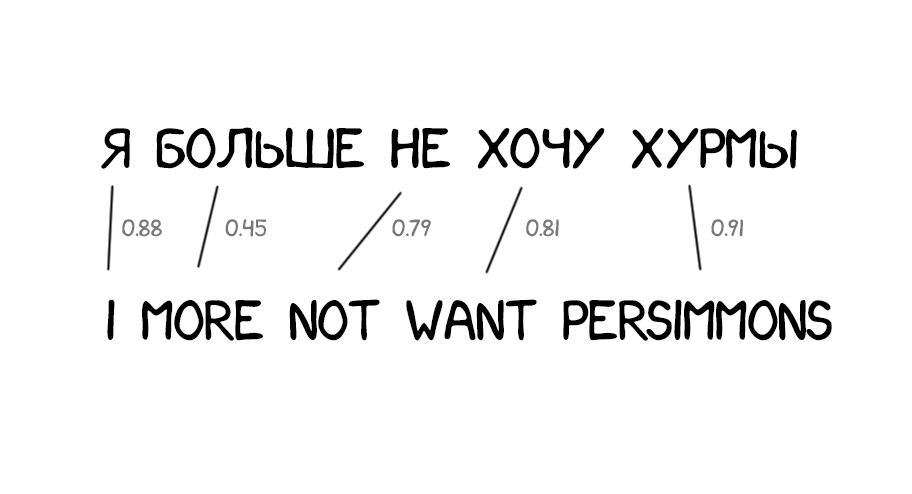
Класичний підхід - ділимо все на слова і вважаємо статистику. Ніякого обліку порядку або перестановок. З хитрощів Model 1 вміла хіба що переводити одне слово в кілька. Der Staubsauger (пилосос) легко перетворювався в Vacuum Cleaner, але назад уже як пощастить.
На Python можна знайти простенькі реалізації: shawa / IBM-Model-1 .
Model 2: облік порядку слів у реченні
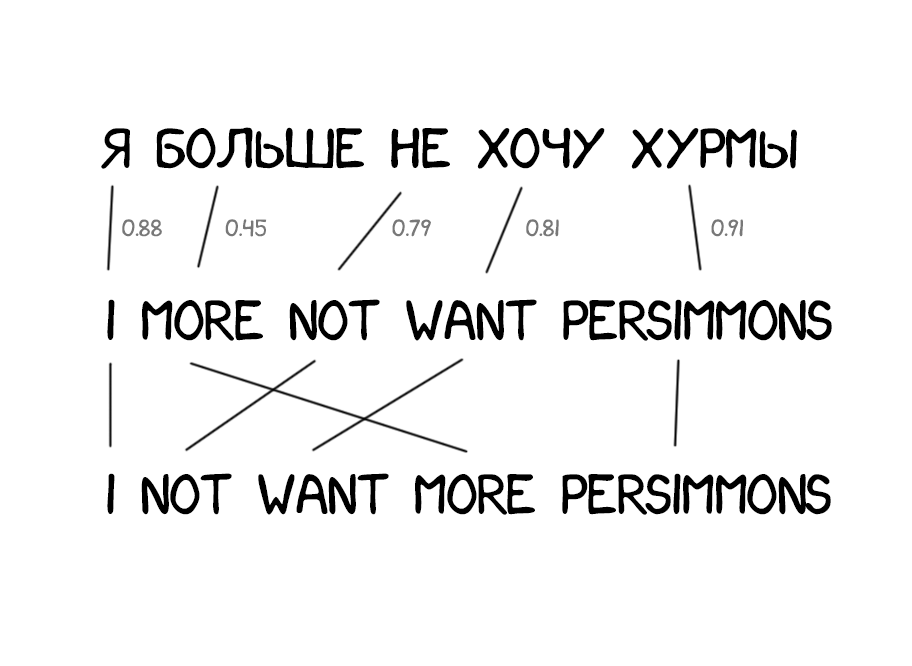
Відсутність знань про порядок слів у мовах стало проблемою для Model 1. У деяких він дуже важливий. Тому в Model 2 стали запам'ятовувати на якому місці з'являється перекладеного пропозиції. Вставляєте проміжний крок - після перекладу машина намагалася переставити слова місцями так, як вона думала буде звучати більш природно.
Стало краще, але все ще хреново.
Model 3: додавання відсутніх слів
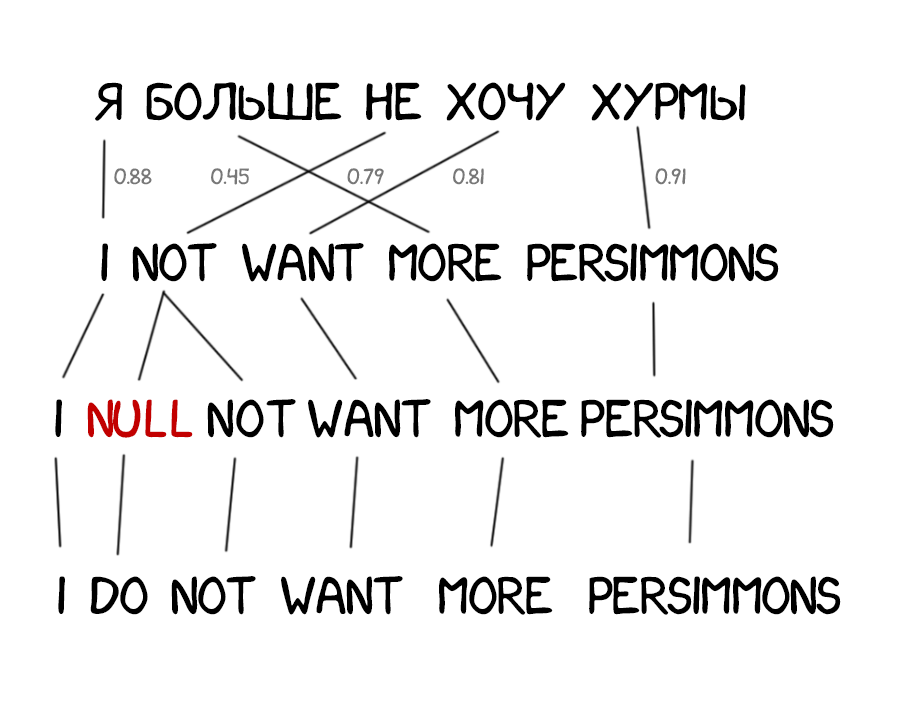
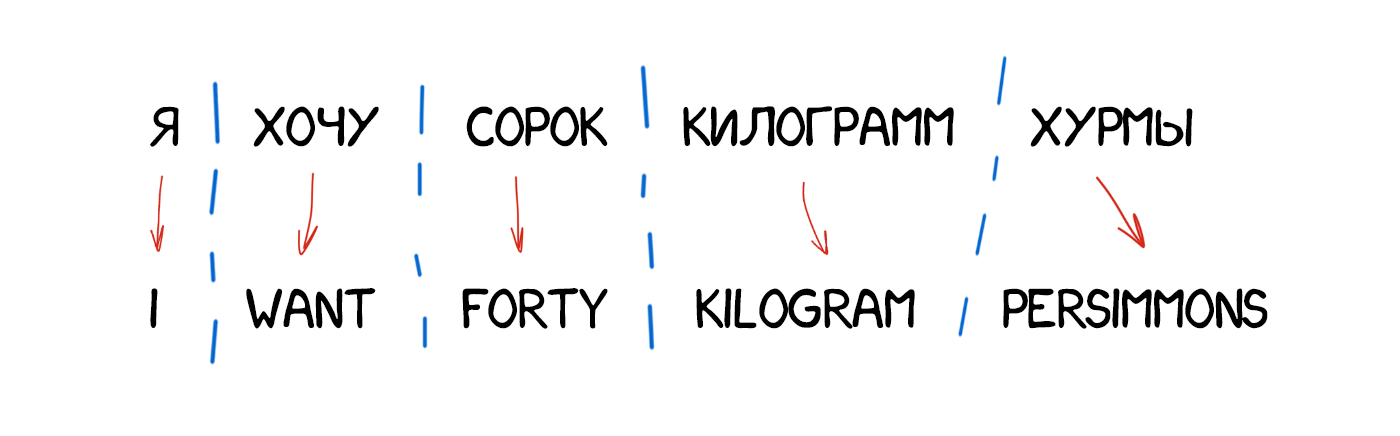
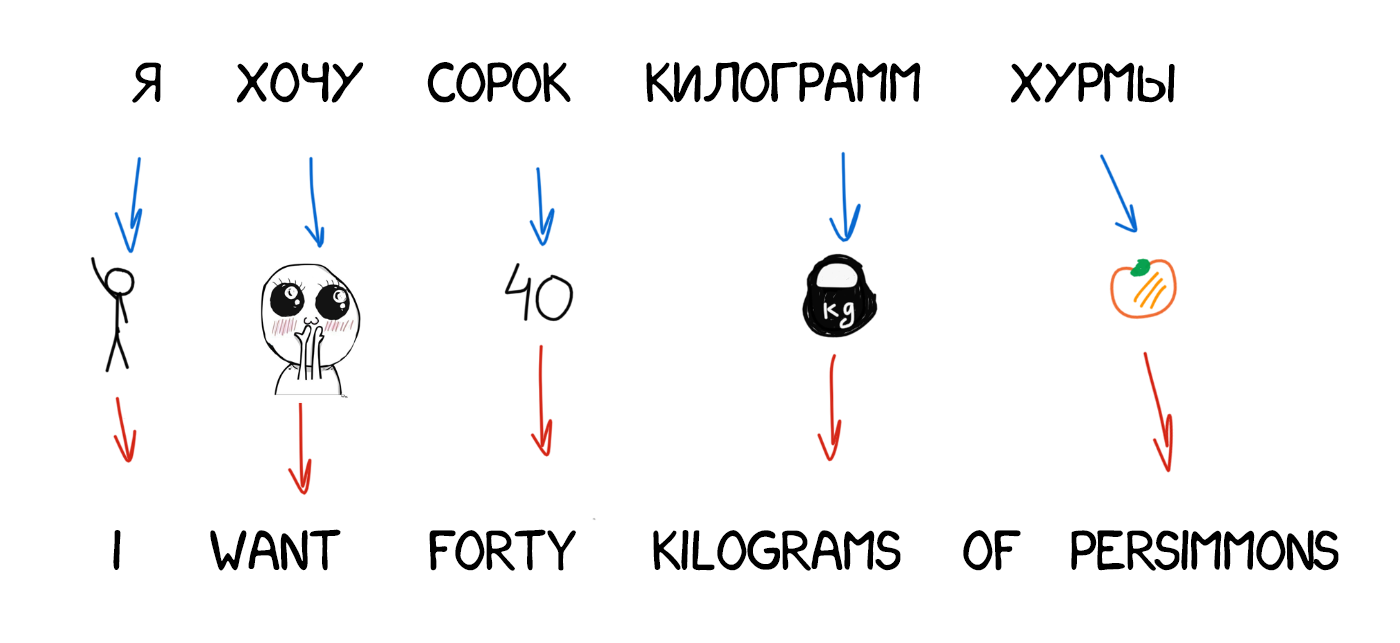
Часто при перекладі з'являються нові слова, яких не було в оригінальному тексті. У німецькій мові раптово вилазять артиклі, в англійському вставляють дієслово do де не попадя. «Я не хочу хурми» → «I do not want persimmons. Щоб вирішити цю проблему в Model 3 додали два проміжних кроку:
- Вставка маркерів (NULL-слів) на ті місця, де машина підозрює необхідність нового слова
- Підбір потрібного артикля, частки або дієслова під кожен маркер
Model 4: перестановки слів
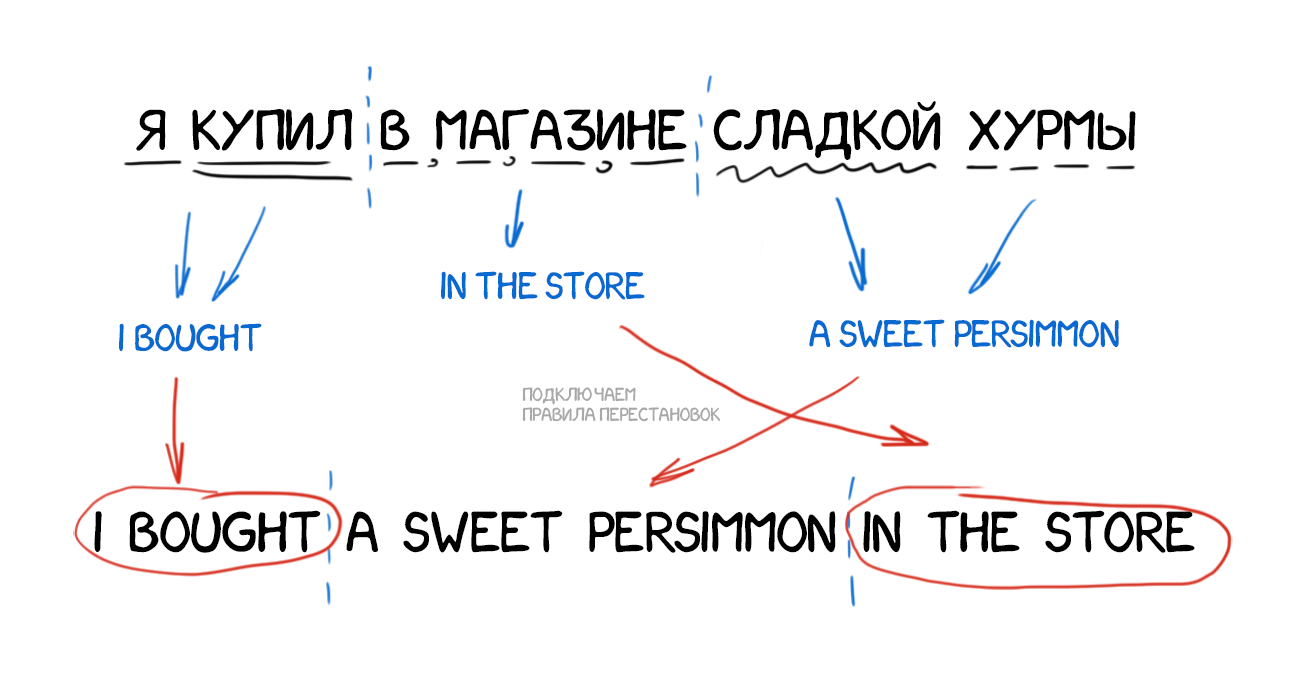
Model 2 хоч враховувала порядок слів у реченні, але нічого не знала про перестановки слів між собою. Часто при перекладі треба, наприклад, поміняти іменник і прикметник місцями. Тут скільки не запам'ятовуй їх порядок по всьому пропозицією - краще не стане. Тому в Model 4 стали враховувати ще й так званий «відносний порядок». Якщо при перекладі два слова постійно змінювалися один з одним - модель це запам'ятовувала.
Model 5: багфіксів
Особливо нічого нового. В Model 5 додали параметрів для навчання і пофіксити проблеми, коли два слова конфліктували за місце в реченні.
Незважаючи на всю революційність, Word-based системи як і раніше нічого не могли вдіяти з відмінками, родом і омонімією. Кожне слово вони переводили єдиним, на їхню думку, вірним способом. Зараз такі системи не використовуються, їх замінив більш просунутий метод - переклад по фразах.
Про омонимию у мене є улюблений жарт:
- Це ваш Ягуар біля під'їзду стоїть?
- Так
- Я доп'ю?
Взяв за основу все принципи перекладу за словами: статистика, перестановки і лексичні хакі. Але для навчання він розбивав текст не тільки на слова, а й на цілі фрази. Точніше N-грами або фраземи - пересічні набори з N слів поспіль. Машина вчилася переводити стійкі поєднання слів, що помітно поліпшило точність.
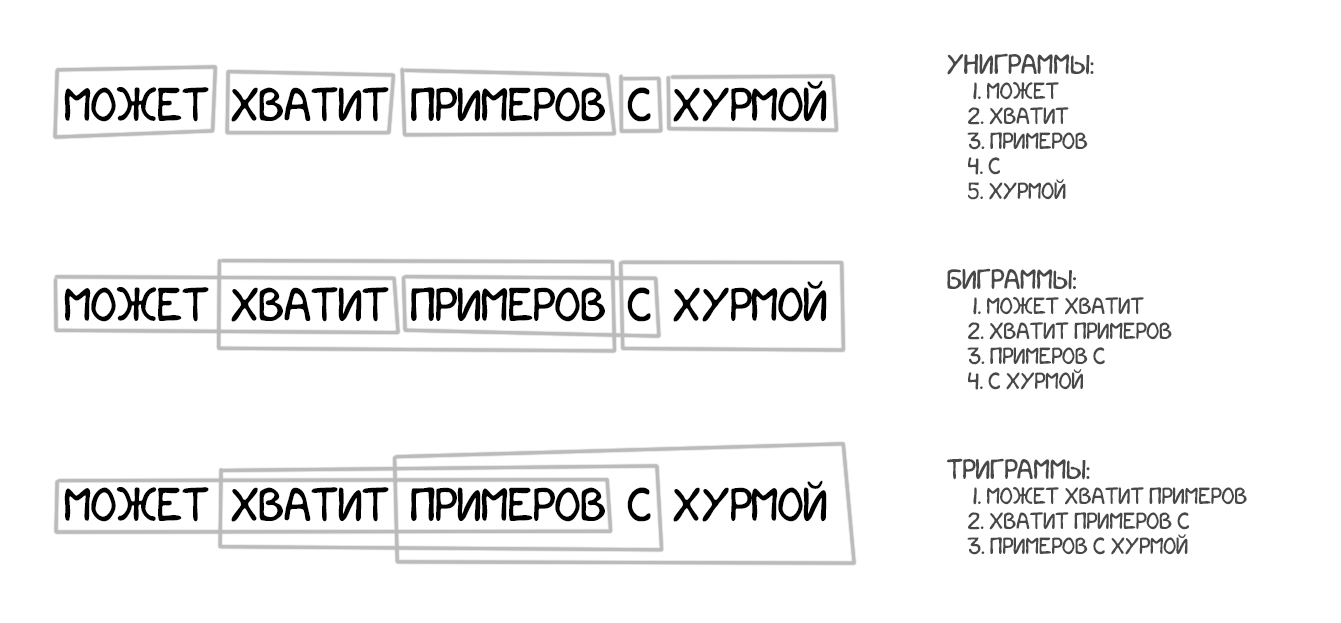
Хитрість методу полягала в тому, що «фрази» не завжди були зрозумілими нам зі школи синтаксичними конструкціями. Як тільки в переклад намагався втручатися людина, яка знає про лінгвістику і будова речень, якість перекладу різко падав. Піонер комп'ютерної лінгвістики Фредерік Йелинек одного разу пожартував з цього приводу: «Кожен раз, коли з команди йде лінвіст, якість розпізнавання зростає».
Крім поліпшення точності, переклад по фразам дав більше свободи в пошуку двомовних текстів для навчання. Для Word-based перекладу було дуже важливо точну відповідність перекладів, що виключало будь-які твори літератури і вільні переклади. Phrase-based прекрасно навчався навіть на них. Багато хто навіть почали парсити новинні сайти на різних мовах і поліпшувати переклад цими текстами.
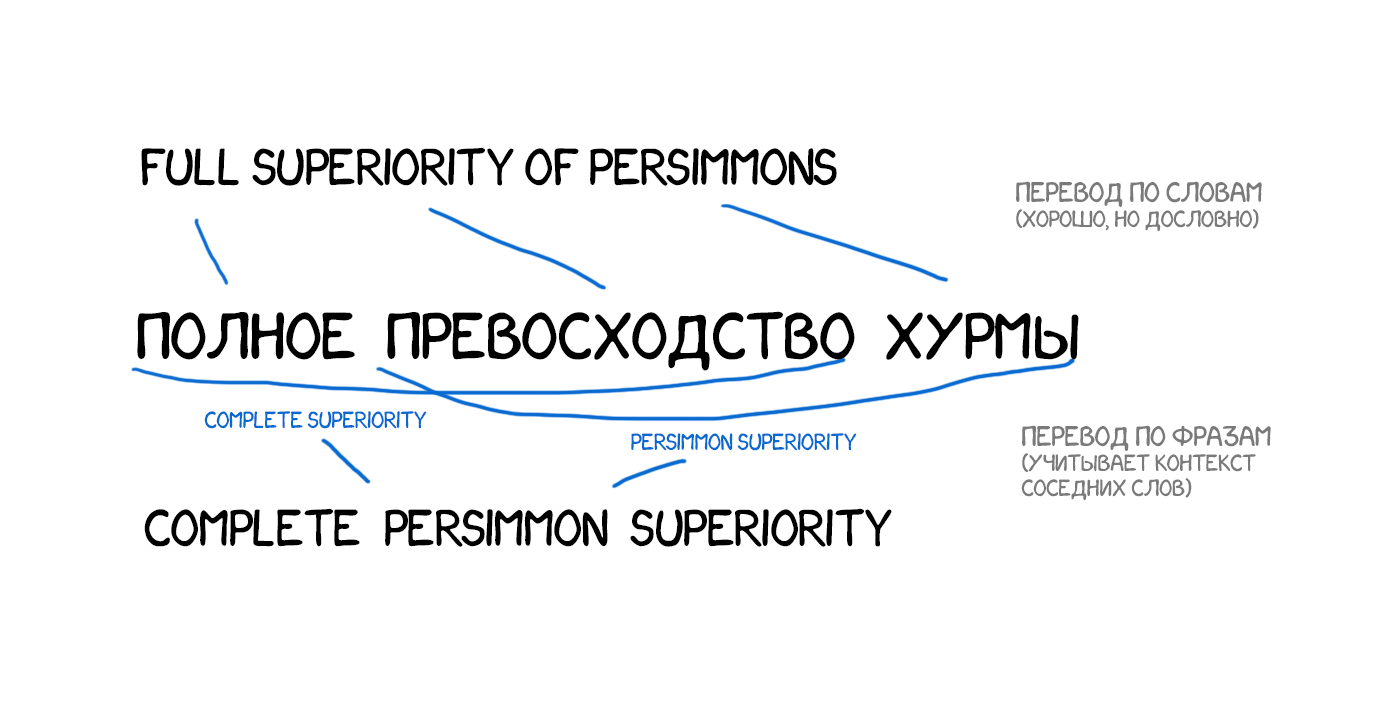
З 2006 року цей підхід почали використовувати всі. Google Translate, Yandex, Bing та інші якісні онлайн-перекладачі працювали саме як Phrase-based аж до самого 2016- го. Кожен з вас може пригадати досвід, коли одне речення Google перекладав на відмінно, літературно переставляючи слова, а на іншому починав гнати повну нісенітницю. Така особливість перекладу по фразам.
Якщо старий добрий Rule-based підхід стабільно давав передбачуваний, хоч і жахливий результат, то статистичні методи бувало дивували і спантеличували. Можна згадати десяток жартів про Google Translate, коли він перекладав «three hundred» як «300» і навіть не переймався. Цей косяк назвали статистичними аномаліями.
Phrase-based переклад став настільки популярним, що коли ви чуєте «статистичний машинний переклад», скоріше за все мається на увазі саме він. Аж до 2016 року в усіх дослідженнях Phrase-based переклад хвалебно називають the state-of-art. Тоді ніхто навіть не підозрював, що в лабораторіях Google вже завозять під цю справу фури з нейросетями, щоб знову змінити наше уявлення про машинний переклад.
Варто коротенько згадати і цей метод. До приходу нейромереж, про синтаксичний переклад багато років говорили як про «майбутнє перекладачів», але досягти успіху він так і не встиг.
Адепти синтаксичного перекладу вірілі в об'єднання підходів SMT и старого трансферного перекладу за правилами. Потрібно навчітіся делать Досить Точний синтаксичний розбір Пропозиції - візначаті підмет и прісудок, залежні члени и вісь це вісь все, а потім побудуваті дерево. Маючі таке дерево, можна навчіті машину правильно конвертуваті фігурі однієї мови в фігурі Іншого, віконуючі решті переклад за словами або фразами. Тільки робити це тепер не руками, а машинним навчанням. У теорії це вирішило б проблему порядку слів назавжди.
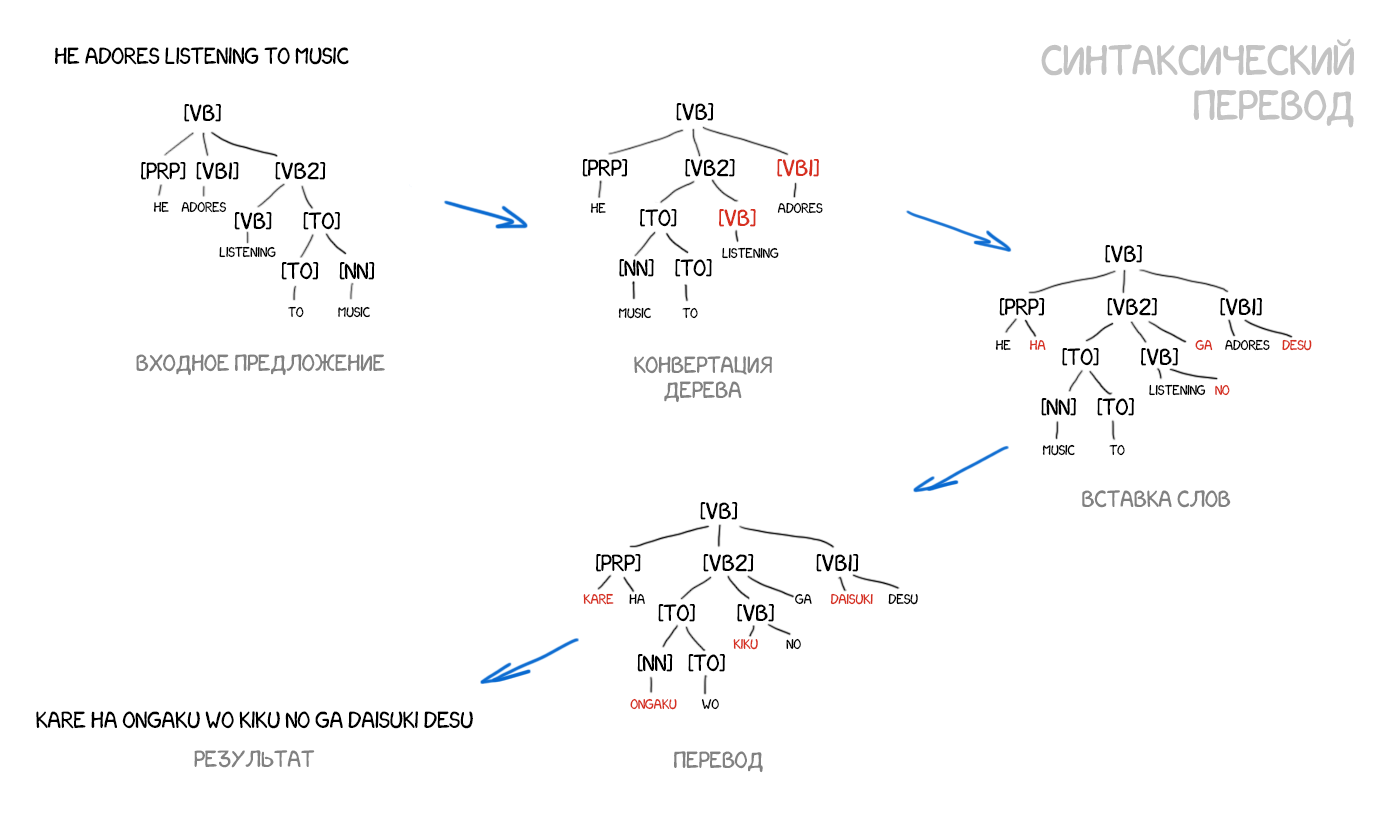
Приклад взятий з Yamada and Knight [2001] і ось цих відмінних слайдів .
Проблема в тому, що хоч людство і вважає проблему синтаксичного розбору давно вирішеною (для багатьох мов є готові бібліотеки), за фактом він працює досить говіння. Я особисто багато разів намагався використовувати синтаксичні дерева для задач складніше виокремлення підмета і присудка, і кожен раз відмовлявся на користь інших методів.
Якщо у вас був хоч один успішний досвід з ними, розкажіть в коментах.
У 2014 році виходить стаття з коротким описом ідеї застосування нейромереж глибокого навчання до машинного перекладу. У верхньому інтернеті її взагалі ніхто не помітив, а от в лабораторіях Google почали активно копати. Через два роки, в листопаді 2016, в блозі Google з'являється анонс , Який і перевернув гру.
Ідея була схожа на перенесення стилю між фотографіями. Пам'ятайте додатки типу Prisma , Які обробляли фоточки в стилі відомого художника? Там не було особливої магії - нейросеть навчили розпізнавати картини художника, а потім «відірвали» останні шари, де вона приймає рішення. Утворені кішочкі, по суті проміжне представлення мережі, і було тієї самої стилізованої картинкою. Вона так бачить, а нам красиво.

Якщо за допомогою нейромережі ми можемо перенести стиль на фото, то що якщо спробувати так само накласти іншу мову на наш текст? Уявити мову тексту як той самий «стиль художника», спробувавши його перенести, зберігши суть зображення (тобто суть тексту).
Уявіть, що я на словах описую вам як виглядає моя собака: середній розмір, гострий ніс, великі вуха, короткий хвіст і гавкає постійно. Я передаю вам набір характеристик собаки і, при досить точному описі, ви зможете навіть намалювати її, хоча ніколи вживу не зустрічали.
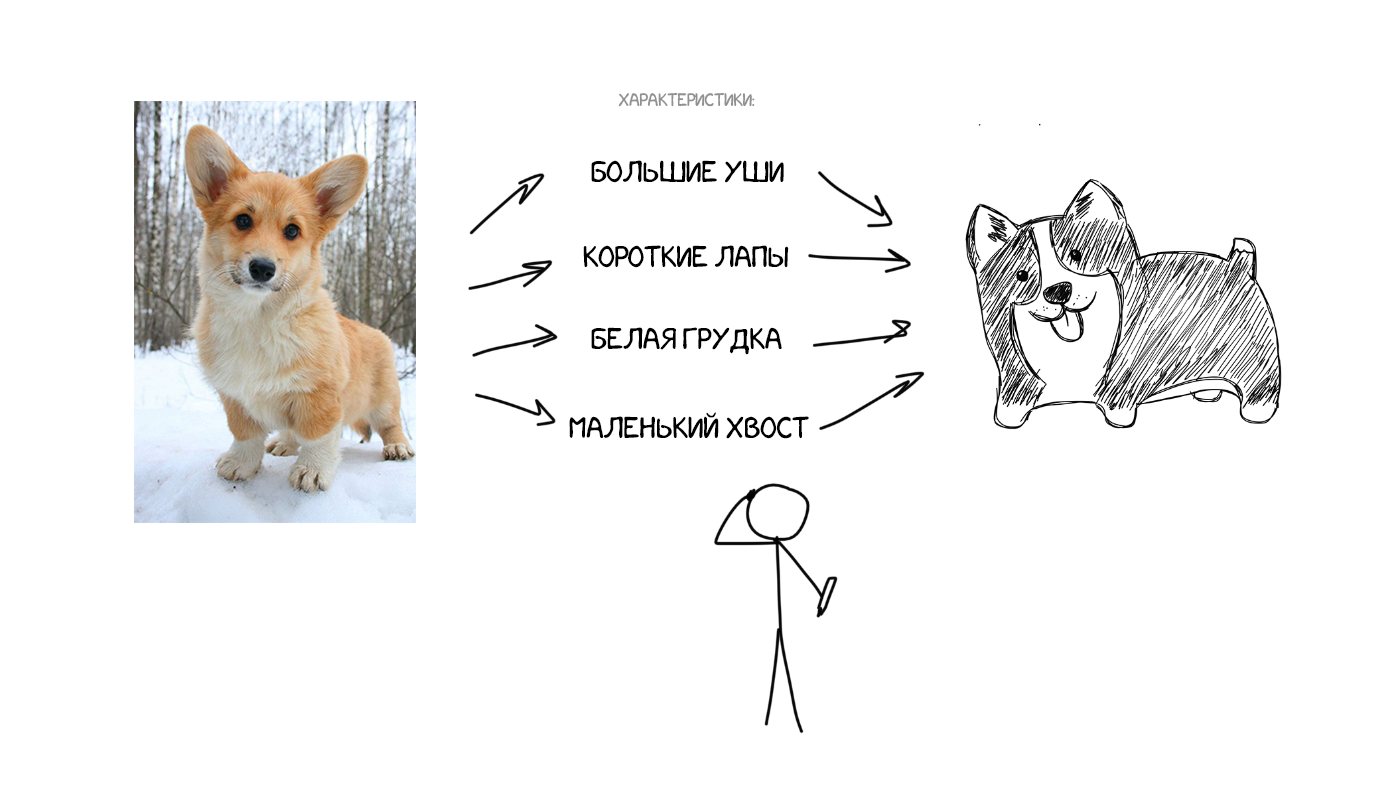
Тепер що якщо уявити вихідний текст як набір таких же характерних властивостей? По суті закодувати його так, щоб потім інша нейросеть - декодер, розшифрувала їх назад в текст, але вже на іншій мові. Ми спеціально навчимо декодер знати тільки свою мову. Він і гадки не має звідки характеристики взялися, але вміє висловити їх, скажімо, на іспанському. Продовжуючи аналогію: яка вам різниця ніж малювати описану мною собаку - олівцями, аквареллю або пальцем по бруду. Малюєте як вмієте.
Ще раз: перша нейросеть вміє тільки кодувати пропозицію в набір циферок-характеристик, а друга тільки декодувати їх назад в текст. Обидві поняття не мають один про одного, кожна знає тільки свою мову. Нічого не нагадує? До нас повернулася ідея інтерлінгва. Та да.
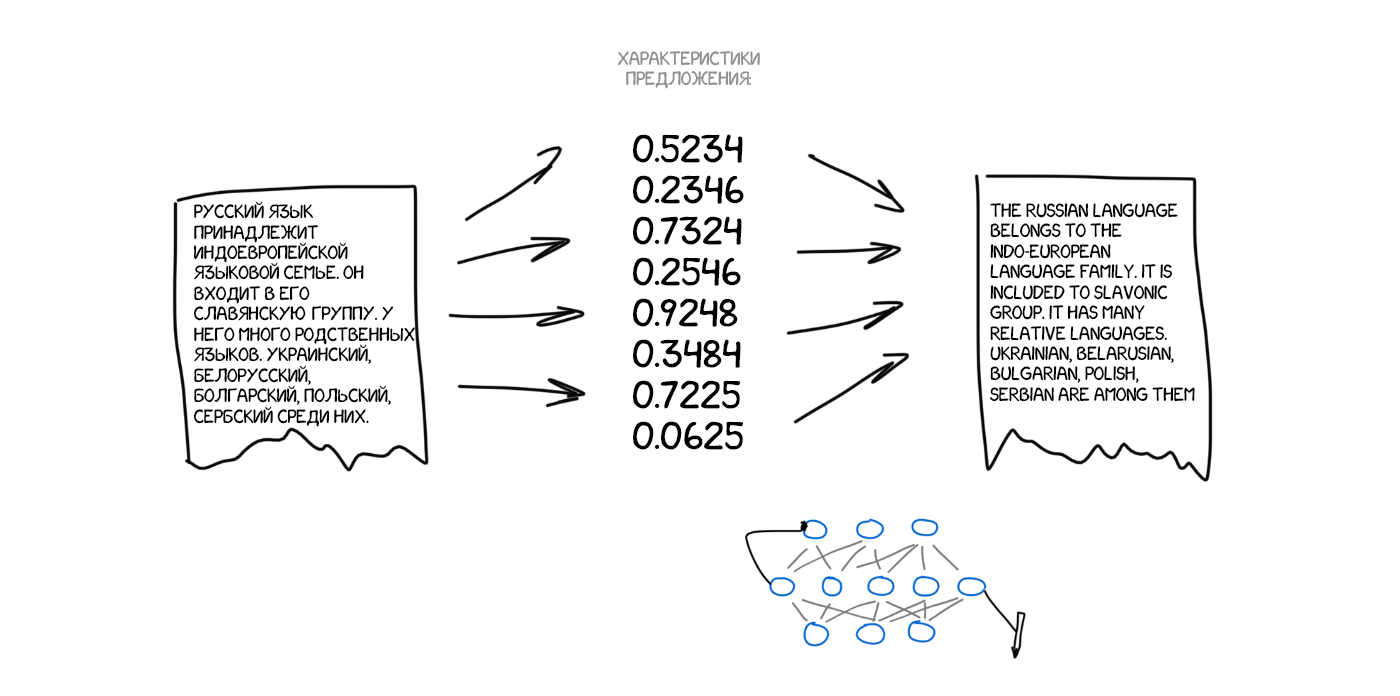
Але як знайти ці характеристики? З собакою все зрозуміло, у неї лапки і інші частини тіла, а з текстами як? Вчені 30 років тому вже намагалися скрафтіть універсальний мовної код, це закінчилося повним провалом.
Але у нас тепер є діплернінг, який якраз цим і займається! Головна відмінність діплёрнінга від класичних нейромереж якраз і було в тому, що його мережі навчаються знаходити характерні властивості об'єктів, не розуміючи їх природи. При наявності досить великий нейромережі і пари тисяч відеокарт в заначці, можна спробувати знайти такі характеристики і в тексті!
Теоретично отримані нейросетями характеристики потім можна віддати лінгвістам і вони відкриють для себе багато нового. Яндекс про це якось розповідав.
Питання тільки в тому, який вид нейромережі використовувати в кодере і декодере. Для картинок відмінно підходять згорткові нейромережі (CNN), тому що працюють з незалежними блоками пікселів. Але в тексті не буває незалежних блоків, кожне наступне слово залежить від попередніх і навіть наступних. Текст, мова і музика завжди послідовні. Для їх обробки краще підходять реккурентное нейромережі (RNN), адже вони пам'ятають попередній результат. У нашому випадку це попередні слова в реченні.
RNN зараз застосовують багато де: розпізнавання мови в Siri (Парс послідовність звуків, де кожен залежить від попереднього), підказки тексту за допомогою клавіатури (запам'ятовуємо попередні і вгадуємо наступне), генерація музики, навіть чатбот.
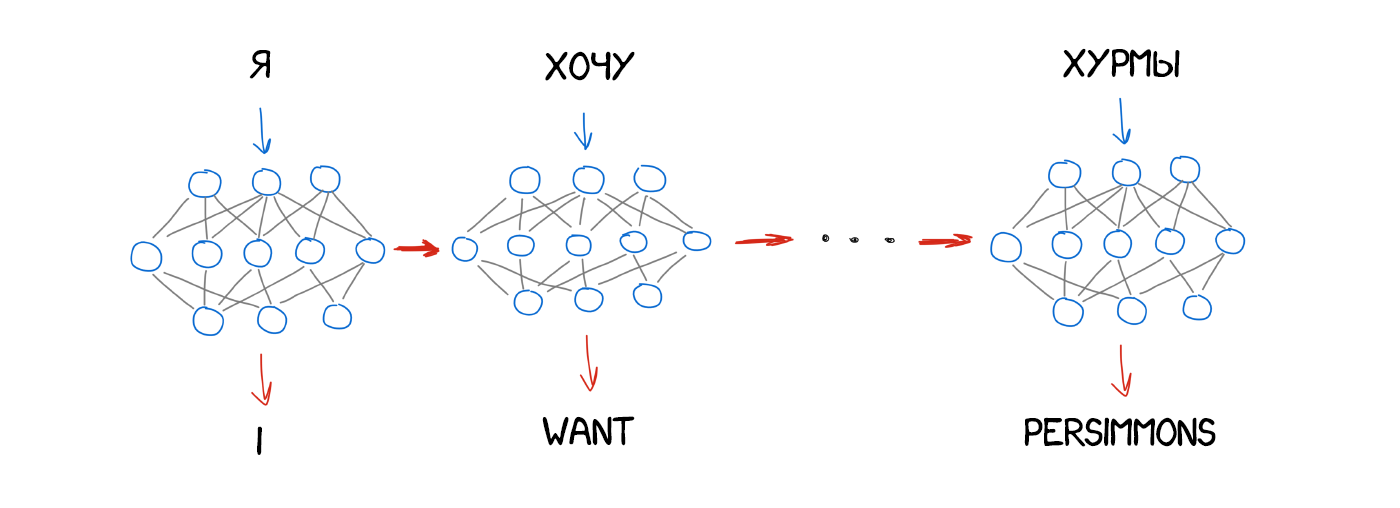
Для задротов типу мене: насправді, архітектури нейронних перекладачів сильно різняться. Спочатку дослідники використовували звичайні RNN, потім перейшли на двонаправлені - перекладач враховував не тільки слова до, а й після потрібного слова. Так було куди ефективніше. Потім взагалі пішли по-хардкору, використовуючи багатошарові RNN з LSTM-осередками для довгого зберігання контексту перекладу.
За два роки нейромережі перевершили все, що було придумано в перекладі за останні 20 років. Нейронний переклад робив на 50% менше помилок в порядку слів, на 17% менше лексичних і на 19% граматичних помилок. Нейросети навіть навчалися самі погоджувати рід і відмінки в різних мовах, ніхто їх цьому не вчив.
Найпомітніші поліпшення були там, де ніколи не існувало прямого перекладу. Методи статистичного перекладу завжди працювали через англійську мову. Якщо ви переводили, наприклад, з російської на німецьку, машина спочатку переганяла текст в англійська, а тільки потім перекладала німецькою. Подвійні втрати. Нейрони перекладу це не потрібно - підключай будь декодер і погнали. Вперше стало можливо безпосередньо переводити між мовами, у яких не було ні одного загального словника.
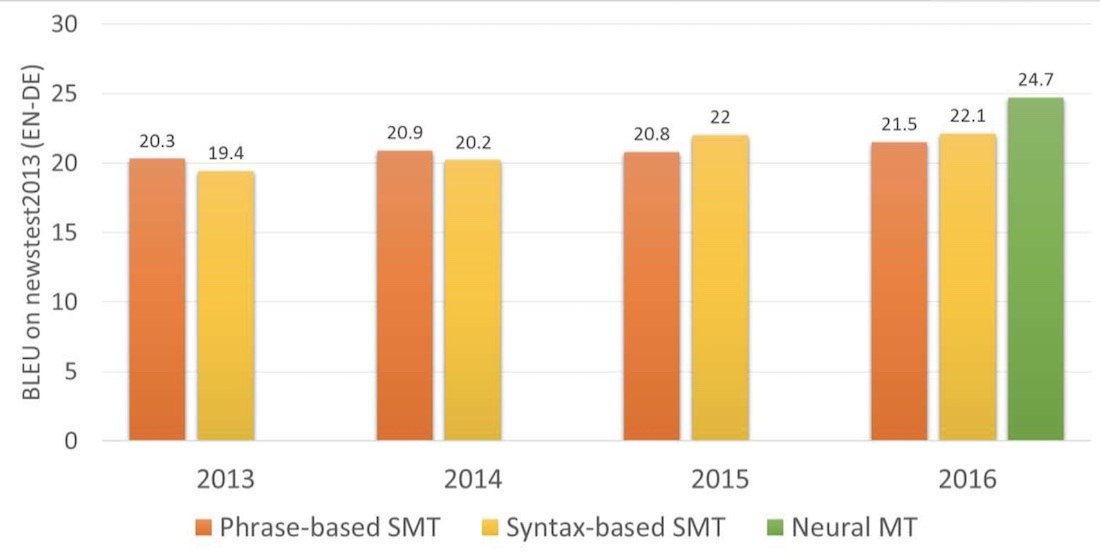
У 2016 році Google включив нейронний переклад дев'яти мов між собою, в 2017 було додано і російська. Google розробив власну систему під нехитрою назвою Google Neural Machine Translation (GNMT), що складалася аж з 8-шарового RNN на вході і такого ж на виході і системи узгодження контексту під назвою Attention Model.
При навчанні вони не просто розбивали пропозиції по фразам і словами, вони ділили навіть самі слова на частини. Цим вони намагалися вирішити одну з головних проблем NMT - вони безпорадні, коли слова немає в їх словниковому запасі. Наприклад «Вастрік». Навряд чи хтось навчав нейросеть переводити мій нікнейм. В цьому випадку GMNT намагається розібрати його на частини і склеїти з них переклад. Хитро.
Hint: той Google Translate, який переводить сайти в браузері, все ще використовує старий Phrase-based алгоритм. Чомусь Google його не оновлюється і на ньому дуже помітні відмінності в порівнянні з онлайн-версією.
В онлайн-версії Google Translate зробили ще й механізм краудсорсингу перекладів. Зараз користувачі можуть вибрати найбільш правильну на їхню думку версію перекладу, і якщо так багатьом вона сподобається, Google буде завжди переводити цю фразу саме так, позначаючи спеціальним значком. Дуже круто працює на коротких повсякденних фразах типу «підемо на обід» або «буду чекати внизу». Гугл знає розмовну англійську краще за мене :(
Перекладач Bing від Microsoft працює як повна копія Google Translate. А ось Яндекс відрізняється.
Яндекс запустив свій нейросетевой переклад в 2017 році. Головною відмінністю вони заявили гибридность. Перекладач Яндекса переводить пропозицію відразу двома методами - статистичним і нейромережевим, а потім за допомогою їхнього улюбленого алгоритму CatBoost знаходить найбільш підходящий.
Справа в тому, що нейронний переклад погано справляється з короткими фразами. Коли вам треба перевести словосполучення типу «бузкова бетономішалка», нейромережі можуть нафантазувати зайвого, а простий статистичний переклад знайде обидва слова тупо, швидко і без проблем.
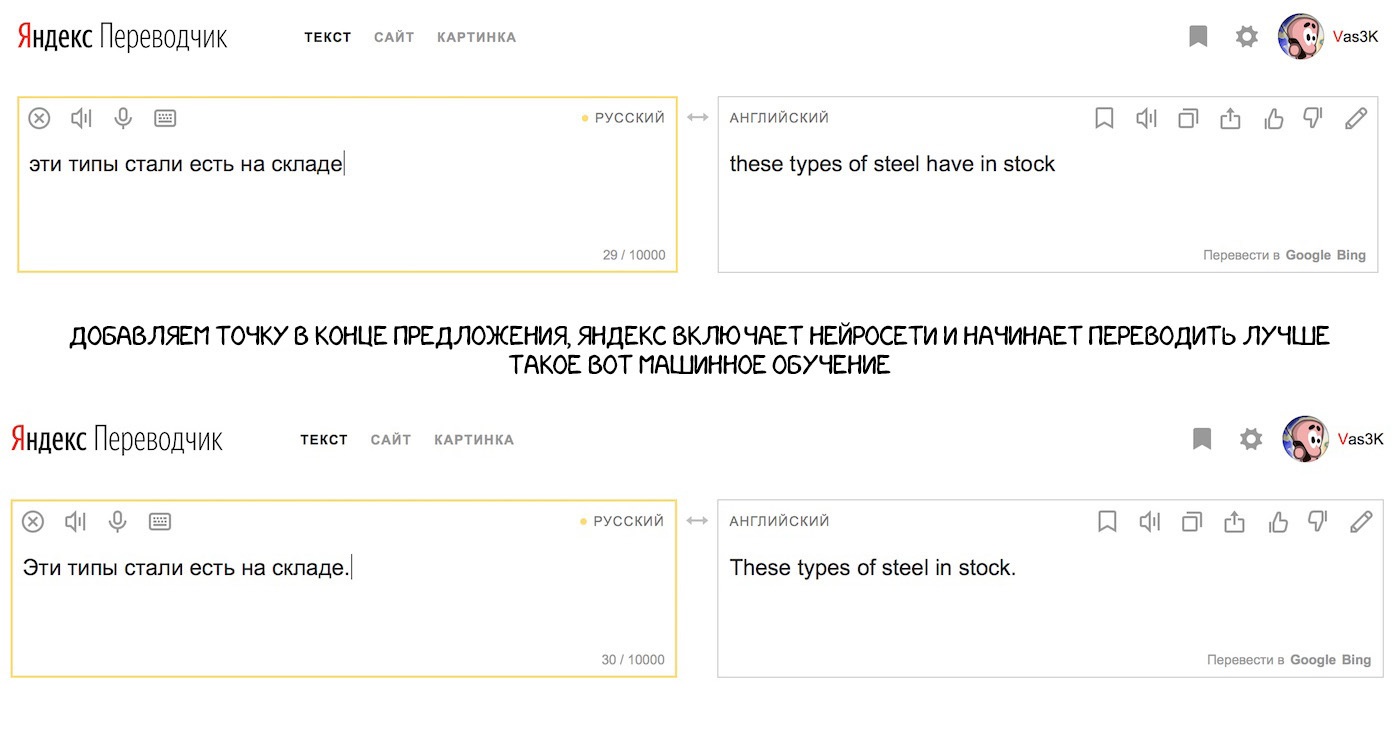
Інших подробиць Яндекс нам не розповідає, відбиваючись нетехническими прес-релізами . Штош Гаразд.
Судячи з усього Google теж використовує SMT для перекладу слів і коротких словосполучень. Вони не згадують цю в статтях, але це очевидно за різницею між перекладами коротких рядків і довгих. Також SMT явно використовується для показу статистики слова.
Всіх і раніше розбурхує ідея «Вавилонської Рибки» - синхронного перекладу мови на льоту. Google робила крок у цьому напрямку, коли анонсувала Pixel Buds, але на перевірку все виявилося погано. Синхронний переклад на льоту відрізняється від звичайного, адже потрібно знати місця, коли почати переводити, а коли сидіти і слухати. Підходів до вирішення цього завдання я ще не зустрічав.
upd: У коментарях насварили, що не пам'ятав Skype з перекладом на льоту. Виправляюся.
Ось ще одне неоране поле на мій погляд: все навчання як і раніше впирається в обмежений набір паралельних корпусів з текстами. Хвалені глубоченние нейромережі все одно навчаються саме на паралельних текстах. Ми не можемо навчити нейромережа, не даючи їй оригіналу. Але людина-то може, починаючи з певного рівня знань мови, поповнювати словниковий запас просто від читання книг або статей, навіть не переводячи їх на свою рідну мову.
Якщо може людина, то і нейросеть, в теорії, теж. зустрічав тільки один прототип, де придумали як змусити навчену одній мові нейросеть кинути на інші тексти, щоб набралася побільше досвіду. Я б і сам спробував, але я дурненький. Так що на цьому все.
А ви?Ось як мені тепер навчити цьому машину?
А що якщо не намагатися кожного разу переводити заново, а використовувати вже готові фрази?
Одна проблема: як машина здогадається, що для das Haus парою є саме house, а не будь-яке інше слово з пропозиції?
Порядок слів-то різний, звідки ми знаємо як саме треба розбити і знайти потрібні слова?
І де стільки взяти?
Здогадайтеся як назвали другу?
Якщо за допомогою нейромережі ми можемо перенести стиль на фото, то що якщо спробувати так само накласти іншу мову на наш текст?
Тепер що якщо уявити вихідний текст як набір таких же характерних властивостей?
Нічого не нагадує?
