






Наша взаимовыгодная связь https://banwar.org/
У продовження статті Використання регулярних виразів (RegExp) в 1С8.х . Заглиблюємося в практику використання регулярних виразів в 1С. Основи роботи з регулярними виразами добре описані в зазначеній публікації. А я спробую відповісти на питання "чому саме регулярні вирази?" на прикладі конкретної робочої завдання.
Зручний і незручний
Перш ніж приступити до безпосереднього розбору практичного завдання хотілося б внести ясність в поняття "зручний" і "незручний" формат на прикладі xml і html. Перший (xml - розширювана мова розмітки) призначений саме для зберігання інформації, в той час як останній (html - мова розмітки гіпертексту) призначений для структурованого відображення інформації.
"У чому ж така велика різниця? І там і там мова розмітки." - резонно помітите ви. Вся справа в значущих тегах. Теги xml призначені для ідентифікації визначеного в них вмісту. наприклад:
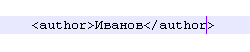
Слово "Іванов", укладену в тег для читаючої xml-файл системи буде означати, що Іванов - автор, з усіма наслідками, що випливають. xml тому і називається "розширюваним", що назви тегів розробник вводить сам з урахуванням потреб по зберіганню / передачі певної інформації.
Теги html служать для того, щоб сказати, що читає системі (браузеру), як потрібно візуалізувати (відобразити у вікні браузера) ті чи інші дані. Теги html кінцеві, тобто розробник сам не може придумати свій тег, інакше браузер його не зрозуміє. наприклад:
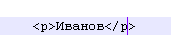
Для браузера буде означати, що слово "Іванов" відображається у вікні браузера як новий параграф з відповідними відступами і т.п. З цього ми зовсім не знаємо, що Іванов - автор. Очевидно, що html - незручний для парсинга (розбору) формат.
Справедливості заради треба зауважити, що html може стати частково зручним форматом якщо тегам почати привласнювати класи або ідентифікатори. Якщо в нашому випадку буде написано наприклад так:

то в принципі з цього можна звичайно зробити висновок, що Іванов - автор, але все-таки це скоріше хитрощі, тому що класи в html природно не призначені для ідентифікації даних - вони призначені для конкретизації візуалізації (відображення) і лише побічно можуть служити для ідентифікації. Тому давайте вважати html незручним форматом для зберігання / передачі інформації.
Все було б добре, АЛЕ на практиці іноді доводиться стикатися з завданнями, коли дані потрібно витягнути саме з таких ось незручних форматів, як html. Наведу приклад (який власне далі і розберу). У мене є розробка Аналізатор мобільного зв'язку . Один з клієнтів предоствіл для вилучення детальних витрат по трафіку саме html, в якому у тегів геть відсутні ідентифікатори або класи, тобто ніякого натяку на можливість ідентифікації. Однак не все втрачено, навіть навпаки, все дуже навіть цікаво виходить за допомогою регулярних виразів. Адже html - це зовсім не набір незв'язної інформації, а цілком собі структуроване вміст, окремі частини якого мають залежності один між одним.
Чому регулярні вирази?
Суть роботи з регулярними виразами зводиться до елементарного розбору рядків і пошуку в них збігів і субсовпаденій. Принадність методу послідовного порядкового розбору очевидна - низькі вимоги до ресурсів комп'ютера.
"Чому саме регулярні вирази?" - зрісся ви. Адже можна використовувати штатні засоби платформи 1С "Знайти", "СтрДліна", "СтрЗаменіть" та ін. Так, можна, але програмний код з використанням регулярних виразів локонічнее і зрозуміліше. Для того, щоб ідентифікувати певні дані в рядку, потрібно буде написати купу "Якщо", "Знайти", "СтрЗаменіть" і т.д. У регулярних виразах весь цей масив коду можна замінити одним шаблоном (патерном).
Ключовим моментом при роботі з регулярними виразами є виявлення унікальної комбінації строкових виразів. Саме комбінація певних строкових виразів і служить ідентіфікацірующім ознакою значущих даних. Поясню. Наприклад, зустрічаючи в розглядуваної файлі таку комбінацію тегів:
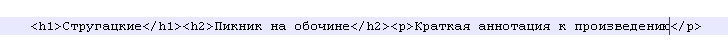
знаємо, що в першому тезі h1 міститься назва автора твору, в другому тезі h2 міститься назва твору, а в третьому тезі p міститься анотація до твору. Тобто кожен раз зустрічаючи в файлі набір цих тегів я заздалегідь знаю що знаходиться в першому, другому і третьому тегах. Повторюся - тут важливо знати, що комбінація унікальна, тобто не повинно бути іншої такої ж комбінації тегів, в яких міститься якась інша інформація або присутній інший порядок даних. Це знання і регулярні вирази дозволяють витягати з таких ось унікальних комбінацій потрібні дані.
Практика
Ніщо так не дозволяє засвоювати матеріал, як практика.
Нижче на скріншоті ви можете спостерігати фрагмент отрисовать в браузері рахунку, надісланого в форматі html:
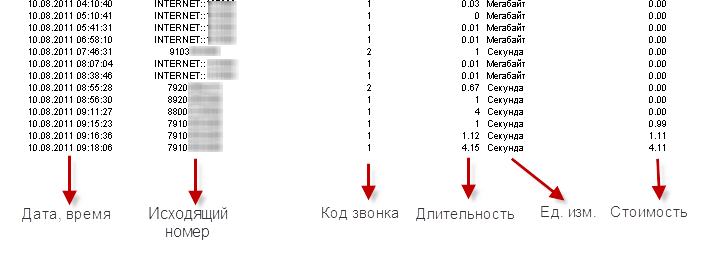
"Чудово, це ж всього-на-всього таблиця і розпарсити її не складе труднощів" - подумаєте ви. Як би не так. Не варто забувати, що це всього лише фрагмент, до і після якого є сила-силенна всякої супутньої інформації, як-то розриви рядків, колонтитули, підсумки, заголовки сторінок і ін. Та ін., Вобщем структурований хаос інформації. І такого хаосу мегабайт на 200.
А тепер ось як одна з рядків виглядає в html коді (рядок довга, тому я зробив перенесення рядків і позначив місця переносів символом "|"):

Хто розбирається в HTML знає, що тег tr позначає рядок в таблиці, а td позначає колонку, точніше осередок в певній колонці певного рядка.
Парсити таке штатними засобами 1С досить важко, простіше написати шаблон на мові регулярних виразів і текст вихідного коду скорочується в рази. Нижче приклад розбору в 1С такого коду за допомогою регулярних виразів (звертаю увагу, що це лише фрагмент коду та я не акцентую увагу на створення в 1С об'єкта для роботи з регулярними виразами - це тепер добре описано у зазначеній мною вище статті):
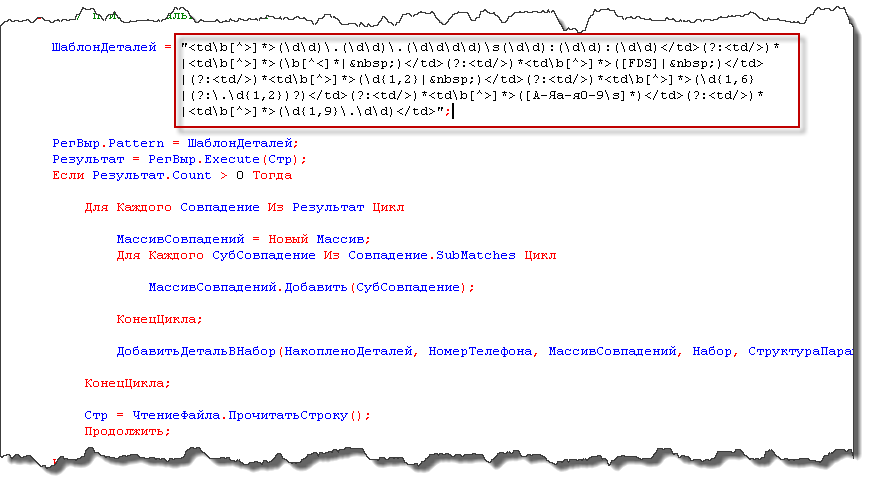
Це власне весь розбір. Далі вже йде робота з витягнутими даними.
Якщо при розборі рядка всі умови регулярного виразу виконані - це значить, що ми розбирали саме рядок деталізації, а значить в МассівеСовпаденій розташовуються в порядку черговості потрібні дані (дата / час, номер співрозмовника, кількість, вартість і т.д.)
Давайте тепер пройдемося по регулярному виразу і переведемо на російську мову умови, задані за допомогою самого нього.

- Шукається тег td всередині якого може бути присутнім опис класів, атрибутів і т.п.
- Шукається послідовність цифр і символів: 2 цифри, точка, 2 цифри, точка, 4 цифри, пробіл, 2 цифри, двокрапка, 2 цифри, двокрапка, 2 цифри. Це ніщо інше як дата і час. Причому все, що знаходиться в круглих дужках запам'ятовується і потім потрапить в МассівСовпаденій, за винятком тих дужок, в яких спочатку йде?:.
- Шукається закриває тег td, після якого йде довільну кількість тегів td до виконання наступного за висловом умови.
- Далі за умовою слід або будь-який символ, крім символу>, або символ "порожньо". Пусто, тому що в осередку може бути порожньо, що буде позначено спеціальним символом. Тут проводиться пошук номера співрозмовника.
- Далі за умовою повинні зустрітися одна з букв F, D, S або знак "порожньо" - це тип дзвінка.
- Далі за умовою повинні зустрітися або 1 цифра, або 2 цифри, або знак "порожньо" - це код дзвінка.
- Далі за умовою слід від 1 до 6 цифр, точка, 1 або 2 цифри. Причому останні дві цифри необов'язкові. Це тривалість дзвінка (кількість).
- Далі за умовою повинні встіретіться будь-яку кількість російських букв, цифр або прогалин до виполененія наступного умови вираження. Це строкове представлення одиниці виміру тривалості дзвінка.
- Далі за умовою йдуть від 1 до 9 цифр і в обов'язковому порядку точка і 2 цифри. Це вартість дзвінка.
- Ну і наостанок закриває тег td.
У чому ж така велика різниця?
Чому регулярні вирази?
Чому саме регулярні вирази?
