






- Путешествие в тысячу миль начинается ... … В дата-центре Amazon Web Services (AWS) в Бордман, штат...
- Лучший путь
- Преодоление лимитов TCP
- Заключение
Путешествие в тысячу миль начинается ...
Наша взаимовыгодная связь https://banwar.org/
… В дата-центре Amazon Web Services (AWS) в Бордман, штат Орегон, в регионе AWS на западе США, где клиентские машины каждую секунду записывают сотни тысяч записей в кластер Aerospike. Это история о том, как улучшился Aerospike 3.8 Перекрестная репликация центра обработки данных (XDR) не останавливайтесь, реплицируя эту значительную нагрузку при записи на другой кластер Aerospike во Франкфурте, Германия, в регионе AWS ЕС (Европейского Союза), на расстоянии около 5000 миль.
Latency Challenge
Наиболее прискорбным фактом жизни в отношении трансатлантических перелетов является шаг сиденья (для людей) и задержка в сети (для данных). Давайте посмотрим на время прохождения сигнала по сети между нашими двумя дата-центрами. Для удобства чтения мы заменили IP-адреса в Бордмане и Франкфурте на 1.2.3.4 и 5.6.7.8 соответственно:
ubuntu @ ip-1-2-3-4: ~ $ ping 5.6.7.8 PING 5.6.7.8 (5.6.7.8) 56 (84) байтов данных. 64 байта из 5.6.7.8: icmp_seq = 1 ttl = 50 раз = 156 мс 64 байта из 5.6.7.8: icmp_seq = 2 ttl = 50 время = 156 мс ^ C --- 5.6.7.8 статистика пинга --- 2 переданных пакета , 2 получено, потеря пакета 0%, время 1002 мс rtt мин / avg / max / mdev = 156,487 / 156,494 / 156.505 / 0,322 мс
Это 156 мс между отправкой сообщения от Boardman во Франкфурт и получением ответа Франкфурта обратно в Boardman.
Проводной протокол Aerospike - это протокол запроса-ответа по TCP-соединению. Чтобы записать запись в кластер, клиент отправляет в кластер запрос на запись, который включает в себя данные записи для записи; в свою очередь, он получает ответ от кластера, который сообщает ему, была ли успешной его операция записи. Если задержка между запросом клиента и ответом кластера очень мала, достаточно простой и надежной схемы для достижения высокой пропускной способности, как показано ниже:
- Отправить запрос № 1
- Ждите ответа № 1
- Отправить запрос № 2
- Ждите ответа № 2
- И т.п.
Давайте рассмотрим, почему это так. Предположим, что клиент и кластер находятся в одной локальной сети; таким образом, задержка составляет 0,2 мс. Это позволяет нам выполнять один цикл запрос-ответ каждые 0,2 мс, в общей сложности 1000 мс / 0,2 мс = 5000 циклов запрос-ответ в секунду - или 5000 TPS. Для более высокой пропускной способности мы можем запустить эту простую схему на нескольких TCP-соединениях параллельно. С двумя TCP-соединениями, управляемыми двумя потоками или одним потоком с использованием неблокирующего ввода-вывода, мы получаем удвоенную пропускную способность: 10000 TPS. Поскольку пропускная способность линейного роста количества TCP-соединений линейна, все, что нам требуется для поддержки 100 000 TPS - это 100 000/5000 = 20 параллельных TCP-соединений. Так традиционно работают клиенты Aerospike. Рисунок 1 ниже иллюстрирует эту схему:
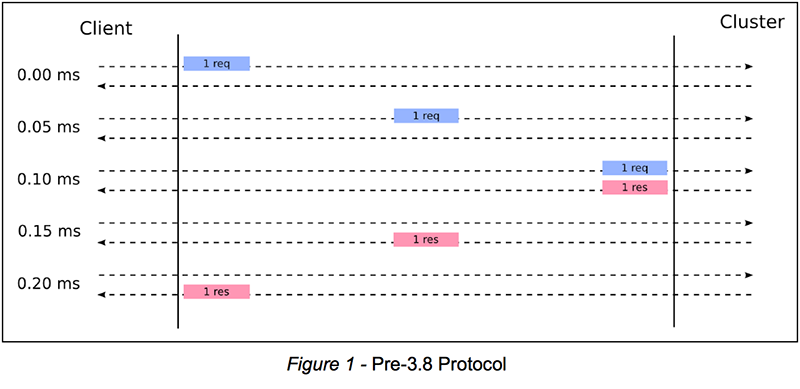
Теперь давайте посмотрим на трансатлантический сценарий с задержкой 156 мс. Здесь выполнение простой схемы на одном TCP-соединении дает 1000 мс / 156 мс = 6,4 TPS. Вот Это Да! Это довольно плохо! Соответственно, для поддержки 100 000 TPS нам потребуется 100 000 / 6,4 = 15 625 TCP-соединений. Это много связей! Мы не сможем использовать отдельные потоки для этого, так как порождение 15 625 потоков нецелесообразно. Хотя неблокирующим вводом-выводом можно управлять этим количеством TCP-соединений, открытие тысяч TCP-соединений по-прежнему представляется расточительным: каждое TCP-соединение требует ресурсов, например буферов памяти, на компьютерах на обоих концах соединения. Более того, разделение одинакового объема данных на меньшее количество TCP-соединений означает отправку большего количества данных на TCP-соединение. Это позволяет стеку TCP / IP создавать большие сегменты TCP, что означает меньшее количество сегментов TCP для - и, следовательно, меньшее количество циклов ЦП, затраченных на один и тот же объем данных.
Таким образом, подход в Aerospike 3.8, который, как мы увидим, заключается в переходе к менее упрощенной схеме запрос-ответ.
Однако, прежде чем мы рассмотрим 3.8, давайте сначала проверим числа, которые мы обсуждали до сих пор. Мы запускаем клиент C эталонный тест на компьютере в Boardman для записи записей размером в один килобайт со скоростью примерно 100 000 TPS в одноузловой кластер Aerospike в том же центре обработки данных:
ubuntu @ benchmark: ~ $ benchmarks -h 1.2.3.4 -n память -k 100000000 -o S: 1000 -w I, 100 -z 55 -L 7,1
Экспериментально мы обнаружили, что требуется 55 потоков, чтобы произвести нагрузку записи приблизительно 100 КТПС - желаемая нагрузка записи для этого эксперимента - отсюда -z 55 в приведенной выше командной строке. При запуске тест периодически выводит такие метрики:
2016-05-26 14:29:06 INFO write (tps = 103253 timeouts = 0 error = 0 total = 3016232 pending = 0) <= 1ms> 1ms> 2ms> 4ms> 8ms> 16ms> 32ms write 100% 0% 0 % 0% 0% 0% 0%
Обратите внимание на пропускную способность записи ~ 100 KTPS. Как мы также видим, созданный сценарий в целом довольно типичен для развертывания Aerospike, то есть мы получаем время отклика менее миллисекунды для операций клиента по каналу LAN.
В качестве иллюстрации мы создали пользовательскую сборку сервера Aerospike, которая реализует простую схему запрос-ответ, описанную выше для 10 параллельных TCP-соединений. Эта измененная сборка производит выходные данные метрик XDR, такие как эти:
26 мая 2016 г. 14:29:06 GMT: пропускная способность INFO (xdr): (xdr.c: 2010) 62: полет 10 : выдача журнала dlog 720000 (дельта 0,0 / с)
В то время как клиент пишет на сервер Aerospike в Boardman, Oregon со скоростью ~ 100 KTPS, XDR выполняет репликацию из Boardman во Франкфурт всего за 62 TPS, что в значительной степени соответствует 10 x 6,4 = 64 TPS, ожидаемым для выполнения нашей простой схемы через 10 параллельных TCP-соединений.
Также обратите внимание на показатель полета, который указывает количество ожидающих запросов. Для каждого из 10 TCP-соединений сервер Oregon Aerospike тратит большую часть своего времени в ожидании ответа из Франкфурта. Вот почему в большинстве случаев существует 10 невыполненных (или находящихся в полете) запросов: по одному на каждое из 10 соединений TCP. Следовательно, перелет 10.
Лучший путь
Вместо того, чтобы бросать много-много TCP-соединений в нашу проблему, давайте теперь попробуем получить максимум от одного TCP-соединения. Вместо того, чтобы писать записи одну за другой, мы могли бы ввести пакетную запись. Представьте себе мир, в котором мы пишем во Франкфурт партиями по 100 штук. Мы объединяем 100 операций записи, отправляем их во Франкфурт по одному TCP-соединению и получаем 100 ответов в ответ. Таким образом, на этом одном TCP-соединении вместо одной операции записи каждые 156 мс нам теперь удается выполнять 100 операций записи каждые 156 мс (то есть 6,4 раза в секунду), в общей сложности 100 x 6,4 = 6400 TPS. Следующий рисунок иллюстрирует эту улучшенную схему:
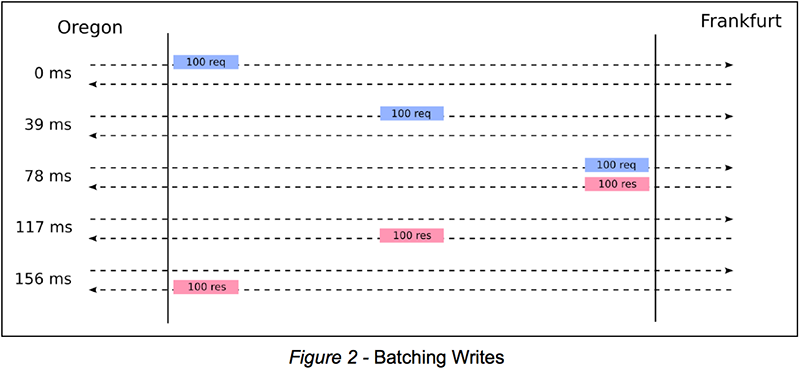
Если мы масштабируем эту идею от 100 до 1000, мы вместо этого получим 1000 x 6,4 = 64 000 TPS для одного TCP-соединения. На первый взгляд может показаться, что большие партии лучше. Однако большие партии приводят к скачкам: Франкфурт бездействует в течение 156 мс, затем получает пакет из 1000 операций, обрабатывает эти операции, отправляет ответный пакетный запрос, а затем становится бездействующим еще на 156 мс до следующей партии. Было бы хорошо, если бы мы могли объединить преимущество нашей простой схемы (подача записей во Франкфурт один за другим, чтобы избежать скачков) с преимуществом пакетной обработки (а именно, с более высокой пропускной способностью).
Как простая схема, так и пакетная схема завершают один полный цикл запрос-ответ по TCP-соединению перед отправкой следующего запроса. Разница заключается лишь в том, что схема, основанная на пакетах, обрабатывает больше записей - точнее, одну полную серию записей - в каждом цикле, что делает его более эффективным, но при этом «более устойчивым». Может быть, было бы неплохо полностью исключить строго последовательное выполнение циклов и вместо этого чередовать их.
До сих пор мы рассматривали только время прохождения туда-обратно линии связи между Бордманом и Франкфуртом. Прежде чем мы рассмотрим чередование, необходимо добавить пропускную способность ссылки к изображению. Предположим, что полоса пропускания составляет 1 МБ (= 1000 x 1000 байтов, в отличие от 1 MiB = 1024 x 1024 байта) в секунду. Далее, предположим, что мы продолжаем работать с записями размером 1 КБ (= 1000 байт). Предположим, что размер результирующих операций записи также равен 1 КБ. Это пренебрегает издержками TCP / IP и протокола Aerospike, но это достаточно близко, и с ним легче вычислять.
Предположим теперь, что мы отправляем операции записи W0, W1, W2,… через одно TCP-соединение во Франкфурт. Однако, в отличие от того, что мы делали раньше, теперь мы не ждем ответа, скажем, на W0, прежде чем отправить W1. Мы просто продолжаем отправлять.
156 мс - одно время туда-обратно - после отправки W0, Boardman получает ответ Франкфурта на W0. Сколько операций записи отправил Boardman за это время, то есть между отправкой W0 и получением соответствующего ответа из Франкфурта? Пропускная способность 1 МБ означает, что мы можем отправлять 1000 наших операций записи объемом 1 КБ в секунду. Соответственно, для отправки одной операции записи требуется 1 миллисекунда; Таким образом, за 156 мс нам удается отправить 156 операций записи. Это показано на рисунке 3 ниже:
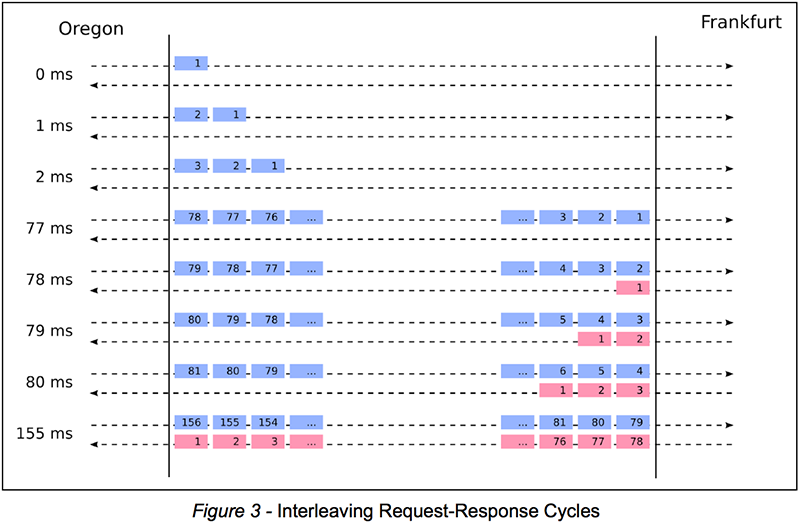
Поскольку мы продолжаем отправлять, мы продолжаем получать ответы на предыдущие записи. Более конкретно, при отправке операции записи Wn мы получаем ответ для Wn-156. Другими словами, ответы отстают от 156 операций. Рисунок 4 ниже иллюстрирует это наблюдение:
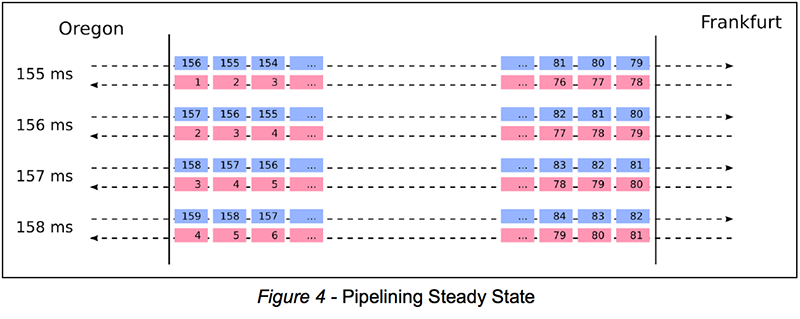
Идея отправки без ожидания ответов, то есть чередования последующих циклов запрос-ответ, называется конвейерной передачей . Действительно, поддержка конвейерной обработки - самое большое улучшение XDR в Aerospike 3.8.
С помощью конвейерной передачи какую пропускную способность мы можем достичь с помощью одного TCP-соединения? Теперь это зависит исключительно от доступной пропускной способности. Конвейерная обработка полностью исключает время прохождения сигнала из уравнения пропускной способности. Пропускная способность - это просто доступная пропускная способность, деленная на размер одной операции: 1 МБ / с / 1 КБ = 1000 TPS.
Теперь давайте увеличим нашу гипотетическую полосу пропускания с несколько скудных 1 МБ / с до 100 МБ / с, то есть примерно до 1 ГБ / с. Теперь мы можем отправлять 100 000 (вместо 1000) наших операций записи объемом 1 КБ в секунду. Другими словами, увеличение доступной полосы пропускания в 100 раз увеличивает пропускную способность на тот же коэффициент. Соответственно, через 156 мс мы теперь отправляем 15 600 (вместо 156) операций записи. Теперь ответы отстают от 15 600 (вместо 156) операций.
Так что же изменится, если наша сетевая связь будет иметь такую же полосу пропускания 100 МБ / с, но в два раза больше времени прохождения сигнала туда и обратно, то есть 312 мс вместо 156 мс? Мы по-прежнему получаем 100 000 операций записи в секунду, поскольку пропускная способность зависит только от доступной пропускной способности. Однако ответы теперь отстают от 31 200 (вместо 15 600) операций - вдвое больше, чем раньше. Опять же, мы видим, что время прохождения туда-обратно не имеет значения для достижимой пропускной способности. Единственное влияние более высокого времени прохождения сигнала туда и обратно - пропорционально более длительное время отклика.
Мы еще раз подтвердим эту теорию, посмотрев выходные данные метрики XDR неизмененной сборки Aerospike 3.8 при той же нагрузке записи клиента ~ 100k TPS, которую мы использовали в нашем эксперименте выше:
26 мая 2016 г. 15:12:15 GMT: пропускная способность INFO (xdr): (xdr.c: 2010) 103798: полет 16817 : выдача dlog 300 (дельта-80,0 / с)
При скорости 103 798 TPS XDR теперь справляется с нагрузкой записи клиента.
Рассматривая операции записи в полете 16 817, мы видим, что число довольно изменчиво; Тем не менее, для следующего расчета мы должны предположить, что он постоянен во времени. Одна передача туда и обратно занимает 156 мс, т. Е. Каждые 156 мс все все 16 817 операций записи в полете будут полностью обработаны и заменены новым набором из 16 817 операций записи в полете. Поскольку это происходит каждые 156 мс, это происходит 6,4 раза каждую секунду. Это означает, что мы выполняем 6,4 x 16,817 = 107 629 операций записи в секунду, что примерно соответствует 103 798 TPS, указанным в выходных данных метрик. Это достаточно близко; имейте в виду, что мы упрощаем расчет, предполагая постоянное количество операций записи в полете.
Преодоление лимитов TCP
Есть еще одна вещь, которую Aerospike 3.8 делает для того, чтобы конвейер мог реализовать весь свой потенциал: немного настройки TCP. Давайте еще раз рассмотрим пример полосы пропускания 100 МБ / с и времени обхода 156 мс. Как обсуждалось выше, мы знаем, что в этом случае задержка отклика составит 15 600 операций. Другими словами, в любой момент времени операции записи в полете будут выполняться в объеме 15 600 x 1000 байт = 15,6 МБ. Это важно из-за окна приема TCP.
Проблемы, с которыми сталкивается TCP в каналах с высокой задержкой, те же самые, которые мы решаем с конвейерной передачей, и его решение почти такое же, как и у нас. В TCP эквивалентом наших запросов являются данные, которые передаются одним концом соединения. Протокол TCP, эквивалентный нашим ответам, - это подтверждения (ACK), отправленные другим концом соединения для полученных данных. Если бы протокол TCP был таким же простым, как простая схема, которую мы обсуждали в начале, он отправил бы блок № 1 передаваемых данных, дождался соответствующего ACK # 1 с другого конца соединения, отправил блок № 2, дождался для ACK # 2 и т. д. TCP, таким образом, столкнется с теми же проблемами с каналами с высокой задержкой, что и наша простая схема.
Таким образом, как и мы, TCP продолжает отправлять данные - не дожидаясь подтверждения. Тем не менее, он делает это только до определенного предела. В то время как мы разрешаем как можно больше операций записи в полете на линии с заданной полосой пропускания и заданной задержкой (например, 15 600 или 31 200 в приведенных выше примерах), при использовании TCP получатель может ограничить объем данных в полете. Если мы хотим, чтобы 15 600 операций записи во время полета во Франкфурт, мы должны убедиться, что конец TCP-соединения во Франкфурте позволяет 15,6 МБ данных в полете. Другими словами, Франкфурт должен объявить о получении окна 15,6 МБ.
Когда Aerospike 3.8 обнаруживает входящее XDR-соединение, он автоматически настраивает приемный буфер соединения таким образом, что стек TCP объявляет достаточно большое окно приема TCP для соединения. Прямо сейчас размер приемного буфера всегда устанавливается на 15 МБ.
Размер буфера приема, который может выбрать программа, ограничен общесистемным пределом в / proc / sys / net / core / rmem_max. Сценарии инициализации Aerospike увеличивают этот лимит до 15 МБ. Таким образом, процесс asd может настроить свои приемные буферы TCP на этот размер для соединений XDR. Пока мы работаем над этим, мы также увеличиваем ограничение для буферов записи TCP до 5 МБ. Это гарантирует, что всегда доступны данные, когда TCP-соединение готово к передаче большего количества данных.
Эти изменения в пределах буфера в / proc заставляют сценарии инициализации Aerospike выводить следующие сообщения:
Увеличение лимита буфера сокета чтения (/ proc / sys / net / core / rmem_max): 212992 -> 15728640
Увеличение лимита буфера сокета записи (/ proc / sys / net / core / wmem_max): 212992 -> 5242880
Хотя все это теоретически позволяет XDR использовать одно TCP-соединение для репликации операций записи через канал с высокой задержкой, в настоящее время мы устанавливаем 64 TCP-соединения (плюс одно дополнительное соединение для обслуживания клиента, всего 65 соединений) следующим образом:
ubuntu @ ip-1-2-3-4: ~ $ netstat -an | grep УСТАНОВЛЕНО | grep 5.6.7.8 | туалет-65
На данный момент конвейер не поддерживает неупорядоченные ответы. Когда Boardman, штат Орегон, отправляет свои операции записи W0, W1, W2 и т. Д. Во Франкфурт, он ожидает получить ответы Франкфурта на операции записи в точно таком же порядке: ответ на W0, ответ на W1, ответ на W2 и т. Д. В Чтобы гарантировать этот порядок, Франкфурт обрабатывает все операции записи XDR с данного TCP-соединения на одном и том же ЦП в строго последовательной последовательности. Таким образом, в настоящее время требуется несколько TCP-соединений для обеспечения параллелизма при обработке операций записи XDR - 64 соединения позволяют задействовать до 64 процессорных ядер. Поддержка конвейерной обработки не по порядку позволит использовать одно TCP-соединение. Однако прежде чем идти по этому пути, мы хотим понять реальные улучшения для наших пользователей с изменениями, описанными выше.
Заключение
XDR в Aerospike 3.8 способен реплицировать значительно более высокую нагрузку записи по каналам с высокой задержкой, чем любая из его более ранних версий. Он использует конвейерную обработку, чтобы полностью исключить время прохождения канала из уравнения пропускной способности. Это позволяет XDR не отставать от операций записи клиента, даже в условиях чрезвычайно высокой нагрузки при записи.
Очевидно, что это улучшение в XDR имеет практические последствия, в частности, для некоторых из наших пользователей с интенсивной записью, имеющих центры обработки данных по всему миру. В реальном мире (по сравнению с этим лабораторным экспериментом) некоторые из наших пользователей сообщили об увеличении пропускной способности XDR в 10 раз или более после обновления с Aerospike 3.7 до 3.8. Как всегда, мы рады узнать ваше мнение о новой версии XDR на нашем сайте. пользовательский форум и услышать о вашем опыте с этой новой технологией.
Похожие
5 десятилетий ПК. IBM PC успех. IBM PC XT 5160... водители группы IBM Первоначально они скептически относились к выходу на рынок ПК. Они опасаются, что небольшой интерес к микрокомпьютерам может поставить под угрозу репутацию IBM, известную по крупным информационным системам для крупного бизнеса. Вот почему они открыли секретный проект Acorn . В рамках этого проекта было создано более десятка независимых бизнес-единиц (IBU), которые работают НЕ делитесь своими фотографиями Google
Все общедоступные Google Фото открыты для общественности , даже если они были предоставлены только определенным людям. Это отличается от Google Диска, где только люди, получившие разрешение через раскрывающийся список «Поделиться с другими», могут просматривать контент. Ниже приведен скриншот моего личного альбома (которым я поделился с одним человеком), открытого в личной вкладке (режим инкогнито) в Firefox. Меня не попросили войти . Мы сравниваем Windows 8 с Windows 10, в чем разница
Поскольку он быстро становится новым стандартом Windows, как и XP до него, Windows 10 становится все лучше и лучше с каждым крупным обновлением. По своей сути, Windows 10 сочетает в себе лучшие функции Windows 7 и 8, исключая некоторые из наиболее противоречивых функций, таких как полноэкранное меню «Пуск», для создания новой и понятной операционной системы. Итак, неважно, хотите ли вы перейти к Windows 10 или только начинаете работать с Creators Update, давайте разберемся с некоторыми основными Безопасность
Проактивная защита Проактивная защита Если Портал размещен на внешнем хостинге, или у сотрудников есть доступ в Интернет, необходимо обеспечить защиту от большинства известных атак на веб-приложения. Для NetGuard Firewall - Android под контролем Part4
1-й дверной менеджер для приложений в третья часть В нашей серии статей «Android под контролем» мы познакомили вас с F-Droid Store, который предлагает критичному пользователю альтернативу «ресурсоемким» приложениям из Play Store. Те, кому удастся преодолеть их удобство, найдут
Комментарии
Получили ли вы его из официального Маркета или законного магазина приложений, такого как Amazon, или из какой-то случайной коллекции приложений?Получили ли вы его из официального Маркета или законного магазина приложений, такого как Amazon, или из какой-то случайной коллекции приложений? Если вы можете ответить «да» на любой (или все) из этих вопросов, просто не устанавливайте приложение. Который лучший"?
Который лучший"? Здесь мы рассмотрим пять лучших онлайн-ресурсов для проверки эффективности антивируса, чтобы помочь вам принять обоснованное решение. Прочитайте больше , обнаружив 99,2 процента последних вредоносных программ для Android. Однако, в отличие от CM Security, он не содержит функций для контроля или наблюдения за деятельностью детей. Его выдающаяся особенность, возможно,
0. Сколько операций записи отправил Boardman за это время, то есть между отправкой W0 и получением соответствующего ответа из Франкфурта?
Так что же изменится, если наша сетевая связь будет иметь такую же полосу пропускания 100 МБ / с, но в два раза больше времени прохождения сигнала туда и обратно, то есть 312 мс вместо 156 мс?
Получили ли вы его из официального Маркета или законного магазина приложений, такого как Amazon, или из какой-то случайной коллекции приложений?
Который лучший"?
Который лучший"?
