






- Складнощі в програмуванні агентів
- ІІ для покеру
- Практична цінність рішень
- завдання учасників
- програма змагання
- Приклад простого бота
- Аналіз реплєєв ігор
- Підготовка рішення до відправки
- класичні підходи
- Підходи на основі машинного навчання
Наша взаимовыгодная связь https://banwar.org/
Про те як вдосконалюється штучний інтелект, можна судити за звичайними ігор. За останні два десятиліття алгоритми перевершили кращих світових гравців: спочатку впали нарди і шашки, потім шахи, «Своя Гра» (Jeopardy!), В 2015 році - відеоігри Atari і в минулому році - Го.
Всі ці успіхи - про ігри з інформаційної симетрією, де гравці мають ідентичну інформацію про поточний стан гри. Це властивість повноти інформації лежить в основі алгоритмів, що забезпечують ці успіхи, наприклад, локальному пошуку під час гри.
Але як справи з іграми з неповною інформацією?
Самим наочний приклад такої гри - покер. Щоб на ділі розібратися з цією грою і алгоритмами вирішення цього завдання, ми організуємо хакатон з написання ігрових ботів на основі машинного навчання. Про те як навчити алгоритми блефувати і спробувати свої сили в покер, не чіпаючи карти, під катом.
Світ повний завдань, пов'язаних з взаємодією між декількома агентами. Історично люди були основними учасниками цих многоагентних ситуацій, проте c розвитком ІІ у нас з'явилася можливість ввести алгоритми в наше повсякденне життя як рівноправних учасників і агентів, з якими можна взаємодіяти. Прямо зараз подібні комп'ютерні агенти вирішують безліч завдань: від простих і нешкідливих як автоматичні телефонні системи, до критично важливих як управління безпекою та навіть управління автономним транспортом. Це дозволяє істотно автоматизувати багато повсякденних процеси, переносячи прийняття рішень на алгоритми і тим самим знижуючи навантаження на людину.
Особливістю багатьох завдань, де ми застосовуємо комп'ютерних агентів, є велика кількість обмежень реального світу, позначається на складності їх програмування. А найважливіше для комп'ютерних агентів - доступ до всієї необхідної для прийняття рішень інформації. Розберемо як це позначається на модельних задачах ІІ - на тому, як наші агенти грають в ігри.
Ігри з асиметрією і неповнотою інформації вимагають значно складніших підходів до прийняття рішень в порівнянні з аналогічними за розмірами іграми з ідеальною інформацією, повністю доступною в будь-який час. Оптимальне рішення в будь-який момент часу залежить від знання стратегії супротивників, залежить від прихованої для нас і доступною тільки їм інформації, оцінити яку можна тільки по їх минулим дії. Однак і їх попередні дії теж залежать від прихованої від них інформації про наших діях і того, як наші дії цю інформацію розкривали. Цей рекурсивний процес показує основну складність в побудові ефективних алгоритмів прийняття рішень.
Складнощі в програмуванні агентів
Під агентом ми будемо розуміти будь-якого автономного учасника процесу, який приймає рішення: як людини, так і комп'ютер. У мультиагентной середовищі агенти взаємодіють між собою і не завжди знають стратегії, цілі та можливості інших агентів. Оптимальну поведінку агента, максимізує свій результат в подібному середовищі, залежить від дій інших агентів. Для побудови ефективного агента в мультиагентной середовищі необхідно адаптуватися до дій інших агентів, моделюючи їх стратегії і навчаючись на основі їх поведінки.
 Щоб агенти могли адаптуватися в реальному часі, їм необхідно вибирати оптимальні дії по ходу досягнення своїх результатів. Якщо використовувати підходи, засновані на навчанні з підкріпленням (Reinforcement Learning), агенти будуть накопичувати нагороду за свої дії. Агенти також будуть балансувати між проходженням своєму запланованого поведінки (exploitation) і експериментальними розвідувальними діями (exploration), намагаючись дізнатися корисну інформацію про стратегії інших гравців.
Щоб агенти могли адаптуватися в реальному часі, їм необхідно вибирати оптимальні дії по ходу досягнення своїх результатів. Якщо використовувати підходи, засновані на навчанні з підкріпленням (Reinforcement Learning), агенти будуть накопичувати нагороду за свої дії. Агенти також будуть балансувати між проходженням своєму запланованого поведінки (exploitation) і експериментальними розвідувальними діями (exploration), намагаючись дізнатися корисну інформацію про стратегії інших гравців.
На додаток і до без того складної постановці завдання агенти зіткнуться і з іншими обмеженнями, пов'язаними з роботою в мультиагентной середовищі з неповною інформацією. Випишемо основні труднощі, з якими зіткнуться наші агенти:
- Обмежене число спостережень. Як правило, агентам буде доступний лише невеликий набір спостережень для навчання. Це особливо критично в реальних додатках, де участь агентів-людей недоступно протягом тривалого часу.
- Стохастичность спостережень. І середовище взаємодії агентів і самі агенти часто схильні до великої кількості випадкових факторів. Виділити корисний сигнал для навчання та адаптації стає особливо важко, якщо поведінка агента є випадковою величиною, що залежить від великої кількості інших випадкових величин.
- Неповнота спостерігається інформації. Це є ключовим властивістю середовища, в якій працюють агенти. Агентам доступний лише частковий і обмежений її огляд, приховує від агентів більшість інформації про світ.
- Динамічна поведінка. З ходом часу агенти можуть адаптуватися до поведінки один одного, нівелюючи досягнутий в ході навчання та адаптації прогрес. Середовище також може змінюватися з плином часу, провокуючи агентів на нові дії, стратегії і поведінку.
Всі ці характеристики накладають серйозні складності на написання комп'ютерних агентів. Моделювання поведінки агентів навіть з однією з цих складнощів є складної наукомісткої завданням, не кажучи про реальні середовищах, де інженерам і авторам таких агентів доведеться зіткнутися з повним переліком цих труднощів. Ми поговорили про загальному випадку складних середовищ - тепер перейдемо до ігор.
ІІ для покеру
Показовим прикладом складного середовища з усіма описаними нами властивостями є гра в покер. У ній є і неповнота інформації про картах, і стратегії беруть участь гравців, і елемент випадковості, пов'язаний з роздачею карт, і інші описані нами проблеми, що виникають під час гри. Більш того, кількість можливих станів гри, що характеризують ігрові ситуації, величезна. Настільки величезне, що лише незначно (в логарифмічною шкалою) поступається Го: в безлімітному Холдеме їх 10160 в той час як в Го їх порядку 10170.
Незважаючи на те, що покер є азартною грою, він визнаний офіційним видом спорту, а національні федерації спортивного покеру є майже в кожній країні (включаючи Росію). Сьогодні у цієї гри є мільйони прихильників по всьому світу, але навіть коли покер ще був далекий від світової популярності, його цінували не тільки гравці, але і вчені. Піонер сучасної теорії ігор Джон фон Нейман був настільки зачарований цією грою блефу і ставок, що говорив:
«Реальне життя вся складається з блефу, з маленьких прийомів обману, з роздумів про те, яких дій очікує від тебе інша людина. Ось що представляє гра в моїй теорії ». Джон фон НейманІсторія розвитку ІІ для гри в покер налічує понад 30 років, але найвидатніші досягнення відбулися буквально в останні 3 роки.
Перші програми і алгоритми гри в покер з'явилися ще в 80-х роках, наприклад, система Orac від Mike Caro, написана ним у 1984 і продемонстрована на турнірі Stratosphere. У 1991 році в Університеті Альберти (Канада) була створена перша в світі дослідницька група, присвячена розвитку ІІ для покеру. У 1997 році ця група продемонструвала свою систему Loki, першу успішну і значиму реалізацію ІІ для покеру. Loki грав на рівні трохи гірше середнього людського гравця, але ця була значуща віха для всього дослідницького напрямку. У 2000-х роках стався зсув парадигми написання ІІ для покерних ботів. Дослідники відійшли від підходів до покеру, натхнених успіхами Deep Blue в шахах (успішно здолав Гаррі Каспарова в 1996 році), до повноцінної методології і постановці завдань моделювання відразу для покеру.
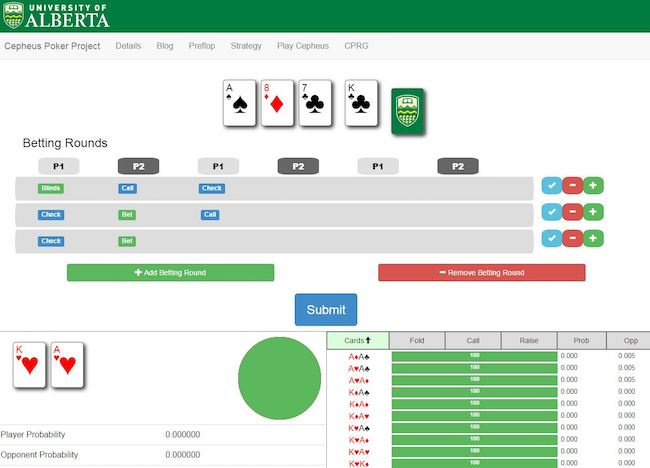 У 2015 році Університет Альберти представив свою систему Cepheus, яка буквально «вирішила» один з видів покеру - лімітний Heads-up покер (спрощена різновид, порядку 1018 ігрових ситуацій). Це значуща віха у розвитку AI, так як це єдина на даний момент гра з неповною інформацією, що має повне оптимальне рішення. Досягти цього вдалося, поставивши Cepheus грати сам з собою протягом двох місяців (схожим чином навчався і AlphaGo, який переміг чемпіона світу з гри Го).
У 2015 році Університет Альберти представив свою систему Cepheus, яка буквально «вирішила» один з видів покеру - лімітний Heads-up покер (спрощена різновид, порядку 1018 ігрових ситуацій). Це значуща віха у розвитку AI, так як це єдина на даний момент гра з неповною інформацією, що має повне оптимальне рішення. Досягти цього вдалося, поставивши Cepheus грати сам з собою протягом двох місяців (схожим чином навчався і AlphaGo, який переміг чемпіона світу з гри Го).
Важливо відзначити, що система не ідеальна в тому плані, що може іноді втрачати фішки в деяких роздачах. Однак при достатній кількості партій Cepheus все одно вийде переможцем. Також важливо помітити, що у безлімітного версії Heads-Up покеру все ще немає аналогічного повного рішення з огляду на надто великого числа ігрових станів.
У цьому році відбулося відразу дві важливі події в світі покеру спамерських пошукових роботів. Університет Альберти представив алгоритм DeepStack для гри в безлімітний Heads-Up покер. Заснований на глибоких нейронних мережах алгоритм успішно здолав безліч людських суперників, включаючи професійних гравців і аналогічно AlphaGo зміг «навчитися» імітувати людську інтуїцію, тривало граючи безліч партій сам з собою.
Трансляція турніру Libratus проти людини
Саме значуща подія 2017 року світі покерних ботів, а можливо і ІІ в цілому. Система Libratus від Університету Карнегі-Меллон з упевненістю здолала професійних гравців в покер - команду, що складається з кращих світових гравців в безлімітний Heads-Up покер. За їхньою оцінкою, алгоритм був настільки хороший, що здавалося ніби він мухлює і бачить карти суперників. Матчі йшли в реальному часі протягом 20-денного турніру, а дії алгоритму вважалися на Пітсбурзькому суперкомп'ютері.
Практична цінність рішень
Незважаючи на гадану маловживаних покерних ботів до реальних завдань, їх розвиток принесло безліч методів, які з карткової гри можна перенести на практику. Алгоритми сучасних покерних ботів, долають кращих людських гравців, універсальні і в цілому спрямовані на навчання агентів в середовищах з неповною і асиметричною інформацією. Їх можна перенести на безліч додатків, де потрібно прийняття рішень в аналогічній за складністю середовищі: від безпеки до маркетингу, в якому можна симулювати торги за аудиторію.
У банківській сфері теж є безліч практичних завдань, де алгоритми, які стоять за передовими покерних ботами знайшли б застосування. Серед таких бізнес-завдань Ощадбанку варто в першу чергу відзначити управління ризик-прибутковістю і ціноутворення на ринку з безліччю інших банків-об'єктів. Але список цих додатків можна легко розширити на такі завдання як Customer Value Management або Next Best Action.

Хакатон з написання ігрових ботів на основі машинного навчання
Щоб прискорити розвиток машинного навчання і штучного інтелекту ми організуємо унікальний хакатон, який передує онлайн-змаганням. Ми запрошуємо фахівців по машинному навчання спробувати свої сили в написанні ігрового штучного інтелекту, який зможе приймати оптимальні рішення в умовах невизначеності і моделювати поведінку інших гравців в покер.
«Штучний інтелект сьогодні повинен служити не тільки для розробки раціональних алгоритмів, але і для моделювання нераціонального поведінки учасників ринку або, як у випадку з нашим турніром, гравців в покер». Олександр Ведяхін, старший віце-президент ОщадбанкуМи сподіваємося, що напрацювання переможців можуть знайти застосування в розробках штучного інтелекту Ощадбанку. Проте, навіть якщо до практичного застосування цих напрацювань можуть пройти роки, подібні хакатони важливі для розвитку науки на подібних модельних задачах.
завдання учасників
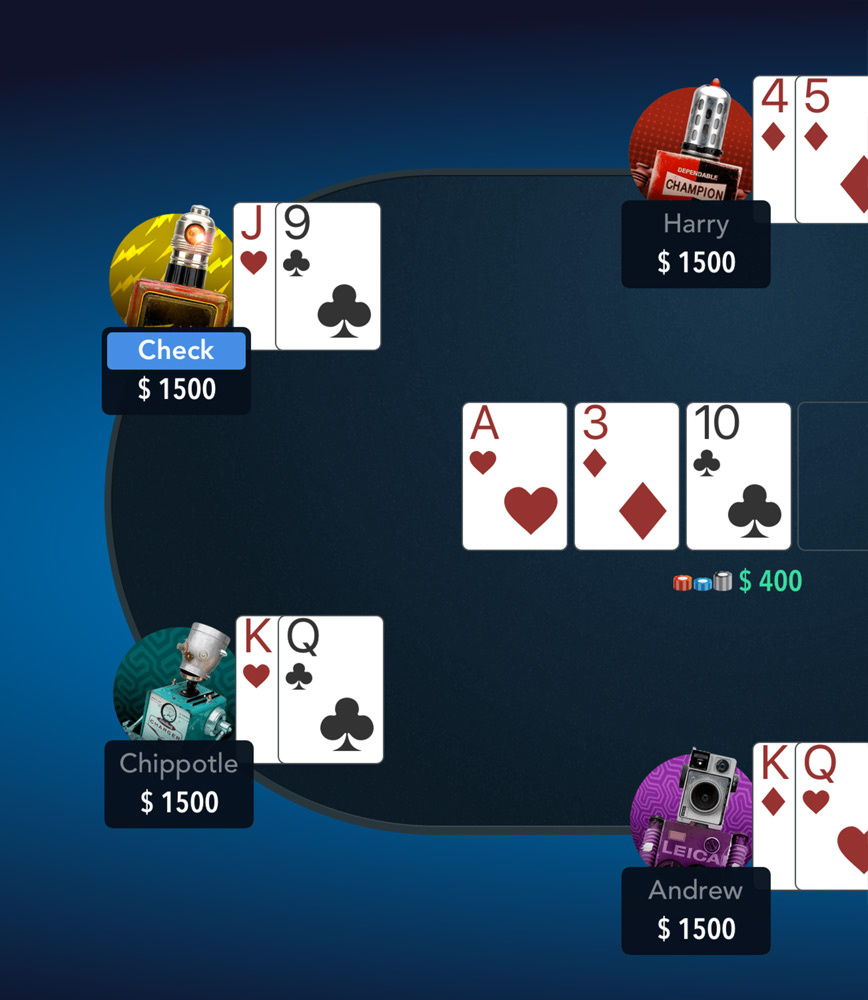 Гра, для якої необхідно написати свого покерного бота, - найбільш популярний різновид покеру: Безлімітний Техаський Холдем (No-limit Texas Hold'em). Вона ж є найскладнішою різновидом гри, до успіхів в якій не підійшла жодна дослідницька група: в ній бере участь не 2, а 9 гравців, а число ігрових комбінацій величезна і досягає 10160.
Гра, для якої необхідно написати свого покерного бота, - найбільш популярний різновид покеру: Безлімітний Техаський Холдем (No-limit Texas Hold'em). Вона ж є найскладнішою різновидом гри, до успіхів в якій не підійшла жодна дослідницька група: в ній бере участь не 2, а 9 гравців, а число ігрових комбінацій величезна і досягає 10160.
Учасникам належить реалізувати агента, який буде грати в покер. Гра покеру є послідовну серію роздач (раундів), яка закінчується, коли всі покерні фішки залишаються тільки у одного гравця, або поки не вийде ліміт числа раундів. У кожній грі беруть участь 9 агентів гравців-ботів.
З агентів учасників будуть випадковим чином формуватися гри і турніри, за підсумками яких будуть визначатися кращі стратегії. У момент початку гри кожному агенту видається банк часу, який можна використовувати для прийняття рішень в перебігу турніру. Якщо агент виходить за ліміт по часу або ж агент надсилає відповідь, що не відповідає протоколу передачі даних, то симулятор здійснює автоматичне скидання карт в кожній з роздач до закінчення турніру.
програма змагання
Змагання проходить в 2 етапи: індивідуальний відбірковий турнір і командний офлайн-хакатон для 100 фіналістів. 100 кращих учасників, які пройдуть відбірковий онлайн-етап, будуть запрошені на закритий офлайн-хакатон.
- 30 серпня, 12:00
Старт онлайн-етапу змагання на платформі конкурсу, початок відправки рішень. - 18 вересня 03:00 (термін продовжено з 15 вересня 23:59)
Закриття онлайн-етапу, рейтингування учасників і відбір фіналістів (топ-100). - 23 вересня, 10:00
Старт оффлайн-етапу Хакатона в Корпоративному Університеті Ощадбанку. - 24 вересня, 16:00.
Фінал Хакатона, підведення підсумків, церемонія нагородження переможців.
Відбірковий онлайн-етап проходить в індивідуальному режимі. Під час онлайн-етапу команда конкурсу надає тестову середу для оффлайн-Хакатона, щоб учасники навчилися писати своїх покерних ботів. Також під час онлайн-етапу кожну північ за розкладом проводиться понад 100 випадкових турнірів, щодня визначають рейтинг пошукових роботів. Під час оффлайн-етапу учасники зможуть формувати між собою команди, а визначають рейтинг учасників турніри відбуватимуться між усіма учасниками щогодини.
Хакатон проходить за безпосередньої участі Академії технологій і даних Корпоративного Університету Ощадбанку, фінал Хакатона пройде в кампусі Корпоративного Університету , Де конкурсантам доведеться доопрацювати свої алгоритми.

Кампус Корпоративного Університету Ощадбанку
Учасникам офлайн-етапу надаються трансфер з Москви на територію кампусу, проживання в готелі, харчування, а також інші послуги і чудові можливості кампуса. Там відбудеться фінал змагання і пройде покер-турнір між ботами за участю професійних коментаторів.
На жаль, в даному змаганні можуть взяти участь тільки громадяни РФ. Логістика до Москви також залишається на самих учасників. У зв'язку з цим, місця в оффлайн-Хакатони тих, хто пройде в топ-100, але з якихось причин не зможе приїхати на оффлайн-етап, будуть передані наступним після них в списку рейтингової таблиці.
Призовий фонд для кращих трьох команд-переможців - 600 000 рублів.
Давайте розберемо, як можна реалізувати свого покерного бота і привести його до перемоги. Для цього нам знадобляться 3 речі:
- Мова програмування, з яким ми впевнено почуваємося (є готові приклади на Python і C ++).
- Симулятор гри в покер, всередині якого буде працювати наш бот. Як симулятора використовується Open-Source бібліотека PyPokerEngine
- Код самого бота, який здійснює ігрові дії всередині симулятора.
Давайте спершу розберемося з ботом, щоб побачити, що це не так складно.
Приклад простого бота
Подивимося на приклад найпростішого бота на мові Python, який кожен раз робить операцію CALL, тобто завжди впевнений у собі і тільки те й робить, що зрівнює ставку опонентів:
from pypokerengine.players import BasePokerPlayer class FishPlayer (BasePokerPlayer): def declare_action (self, valid_actions, hole_card, round_state): call_action_info = valid_actions [1] action, amount = call_action_info [ "action"], call_action_info [ "amount"] return action, amount def receive_game_start_message (self, game_info): pass def receive_round_start_message (self, round_count, hole_card, seats): pass def receive_street_start_message (self, street, round_state): pass def receive_game_update_message (self, action, round_state): pass def receive_round_result_message (self, winners, hand_info, round_state): pass
Бот є об'єктом, в якому реалізовані методи-обробники ігрових подій і метод вибору дії в момент ходу бота declare_action. Детальніше про реалізацію ігрових стратегій можна прочитати в документації до бібліотеки .
Розробка ігрових стратегій доступна не тільки на мові Python і може бути здійснена на будь-якому іншому мовою програмування. Опис API і керівництво по створенню ботів читайте в керівництві з підготовки ботів .
Щодня о 00:00 MSK проводиться турнір між усіма відправленими в систему ботами. Якщо учасник відправив кілька агентів, то враховується тільки його останнім відправлене рішення.
Під час турніру кожен бот грає серію ігор з випадковими суперниками - ботами інших учасників. Таблиця результатів будується по спадаючій середньої суми залишилися фішок у бота за підсумками всіх ігор за турнір.
У турнірній грі беруть участь рівно 9 спамерських пошукових роботів. Максимальне число раундів - 50. На початку гри кожен бот отримує 1500 фішок, розмір малого блайнда - 15.
Це відповідає наступним параметрам раунду в PyPokerEngine:
config = setup_config (max_round = 50, initial_stack = 1500, small_blind_amount = 15)
Аналіз реплєєв ігор
По закінченню турніру, учасникам буде доступні архіви з журналом ігор всіх ботів. Таким чином, ви зможете проаналізувати стратегію своїх опонентів, переглядаючи їх дії по час гри. Однак пам'ятайте, що інші учасники також можуть аналізувати стиль гри вашого бота і до наступного турніру влаштувати вашій боту засідку.
Приклад файлу з реплєєв гри: example_game_replay.json
Реплєї гри записуються у вигляді JSON-об'єкта з полями:
rule: параметри гри
seats: інформація про ботах, зокрема для кожного бота вказано його ім'я name - це ім'я відповідає учаснику, який відправив бота
rounds: список всіх раундів із зазначенням дій, скоєних ботами
Підготовка рішення до відправки
Як середовище для запуску ботів використовується спеціально підготовлений docker-образ. У перевіряє систему необхідно відправити код бота, запакований в ZIP-архів.
Приклад архівів:
→ example-python-bot.zip
→ example-cpp-bot.zip
У корені архіву обов'язково повинен бути файл metadata.json такого змісту:
{ "Image": "sberbank / python", "entry_point": "python bot.py"}
Тут image - назва docker-образу, в якому буде запускатися рішення, entry_point - команда, за допомогою якої необхідно запустити рішення. Для програми-бота поточної Директорією буде корінь архіву, крім виконуваного файлу ви можете покласти будь-які інші допоміжні. Обмеження на розмір архіву - 1Гб.
Практично для будь-якої мови програмування існує docker-оточення, в якому ви можете запустити свого бота:
- sberbank / python - Python3 з встановленим великим набором бібліотек
- gcc - для запуску компільованих C / C ++ рішень ( докладніше тут )
- node - для запуску JavaScript
- openjdk - для Java
- mono - для C #
- Також підійде будь-який інший спосіб, доступний для завантаження з DockerHub
Виконується команда обмінюється з симулятором гри через stdin / stdout. Симулятор передає по одному події в рядку stdin, в форматі event_type <\ t> data, де data - JSON-об'єкт з параметрами події. Приклад вхідних даних , Які симулятор подає в stdin. Опис подій і їх параметрів .
У відповідь на подію declare_action бот повинен у відведений час відповісти в stdout рядком у форматі:
action <\ t> amount
Тут action - одне з доступних гравцеві дій (fold, call, raise), amount - кількість фішок для дії raise, 0 в інших випадках.
У разі використання буферизованного введення / виведення, не забудьте скидати буфер (flush ()) після запису дії в stdout. Інакше симулятор може не отримати повідомлення і у бота вийде ліміт по часу.
Розробку бота на мові Python найзручніше робити за допомогою бібліотеки PyPokerEngine як показано в прикладі вище. Запуск при цьому рекомендується робити в docker-оточенні sberbank / python , В якому встановлений Python 3, а також великий набір бібліотек, включаючи безпосередньо PyPokerEngine і джентельменський набір data scientist-а: numpy, scipy, pandas, sklearn, tensorflow, keras. Повний список встановлених python-пакетів можна знайти в цьому файлі .
Повний код прикладу покерного бота на python доступний нижче.
bot.py import sys import json from pypokerengine.players import BasePokerPlayer class MyPlayer (BasePokerPlayer): # Do not forget to make parent class as "BasePokerPlayer" # we define the logic to make an action through this method . (So this method would be the core of your AI) def declare_action (self, valid_actions, hole_card, round_state): # valid_actions format => [raise_action_info, call_action_info, fold_action_info] call_action_info = valid_actions [1] action, amount = call_action_info [ "action "], call_action_info [" amount "] return action, amount # action returned here is sent to the poker engine def receive_game_start_message (self, game_info): pass def receive_round_start_message (self, round_count, hole_card, seats): pass def receive_street_start_message (self, street, round_state): pass def receive_game_update_message (self, action, round_state): pass def receive_round_result_message (self, winners, hand_info, round_state): pass if __name__ == '__main__': player = MyPlayer () while True: line = sys. stdin.readline (). rstrip () if not line: break event_type, data = line.split ( '\ t', 1) data = json.loads (data) if event_type == 'declare_action': action, amount = player .declare_action (data [ 'valid_actions'], data [ 'hole_ca rd '], data [' round_state ']) sys.stdout.write (' {} \ t {} \ n'.format (action, amount)) sys.stdout.flush () elif event_type == 'game_start': player.set_uuid (data.get ( 'uuid')) player.receive_game_start_message (data) elif event_type == 'round_start': player.receive_round_start_message (data [ 'round_count'], data [ 'hole_card'], data [ 'seats' ]) elif event_type == 'street_start': player.receive_street_start_message (data [ 'street'], data [ 'round_state']) elif event_type == 'game_update': player.receive_game_update_message (data [ 'new_action'], data [ ' round_state ']) elif event_type ==' round_result ': player.receive_round_result_message (data [' winners '], data [' hand_info '], data [' round_state ']) else: raise RuntimeError (' Bad event type "{}" '.format (event_type))
metadata.json { "image": "sberbank / python", "entry_point": "python bot.py"}
Для С \ С ++ також зверніть увагу на інструкцію по запуску ботів на компільованих мовах. Повна документація по підготовці ботів до відправки доступна тут .
За більш ніж 30-річну історію розвитку покерних ботів було створено кілька сімейств підходів в розробці стратегій в покер.
класичні підходи
Одним з найбільш простих в реалізації і найменш витратних за часом є експертна система. По суті це набір фіксованих IF-THEN правил, який відносить ігрову ситуацію до одного із заздалегідь визначених класів. Залежно від сили зібраної комбінації система пропонує прийняти одне з безлічі доступних рішень.
Також це завдання можна вирішувати суто математичним методом і в кожен момент часу розраховувати оптимальне рішення з точки зору рівноваги Неша. Однак, рішення буде оптимальним в тому випадку, якщо рішення інших учасників теж оптимальні. Пошук такого рішення є ресурсовитратності, тому на практиці його можна використовувати тільки разом з великим кол-вом обмежень в правилах. Наприклад, в лімітному техаському холдеме для двох агентів або при виникненні певних ігрових ситуацій.
Підходи на основі машинного навчання
Більш ефективною є експлуатаційна стратегія, яка розділяє опонентів на кластери і проти кожного кластера реалізується контр-стратегія. Більшість хороших гравців в покер використовують саме такий підхід. Але, на відміну від людини, у комп'ютера є перевага в тому, що він може перебрати величезна кількість випадків гри і при правильному прогнозуванні поведінки суперників прийняти максимально вигідне рішення з точки зору математичного очікування. Для прогнозування поведінки опонентів в такому випадку може добре допомогти збір статистики ігор в минулих матчах і реалізація алгоритмів машинного навчання. На жаль авторів алгоритмів, перебрати всі можливі наслідки подій в більшості ігрових ситуацій не вийде навіть у потужних комп'ютерів, тому потрібно використовувати алгоритми оптимізації, такі як Monte Carlo Tree Search . Приклад реалізації подібної стратегії .
Нарешті, можна підійти до створення стратегії ще більш абстрактно і реалізувати нейросеть, на вході у якій будуть параметри ігрової ситуації, а на виході - безліч можливих рішень. До мінусів цього підходу варто віднести те, що в цьому випадку буде потрібно великий набір даних для навчання. Цей мінус можна нівелювати, запустивши нейросеть грати саму з собою на подобу підходу AlphaGo, але потрібно бути готовим до більш ніж однієї доби навчання і моделювання. Про більш складні наукові підходи до створення покерних ботів можна почитати статті професорів з канадського університету Альберти , Які вирішують цю задачу вже не одне десятиліття.
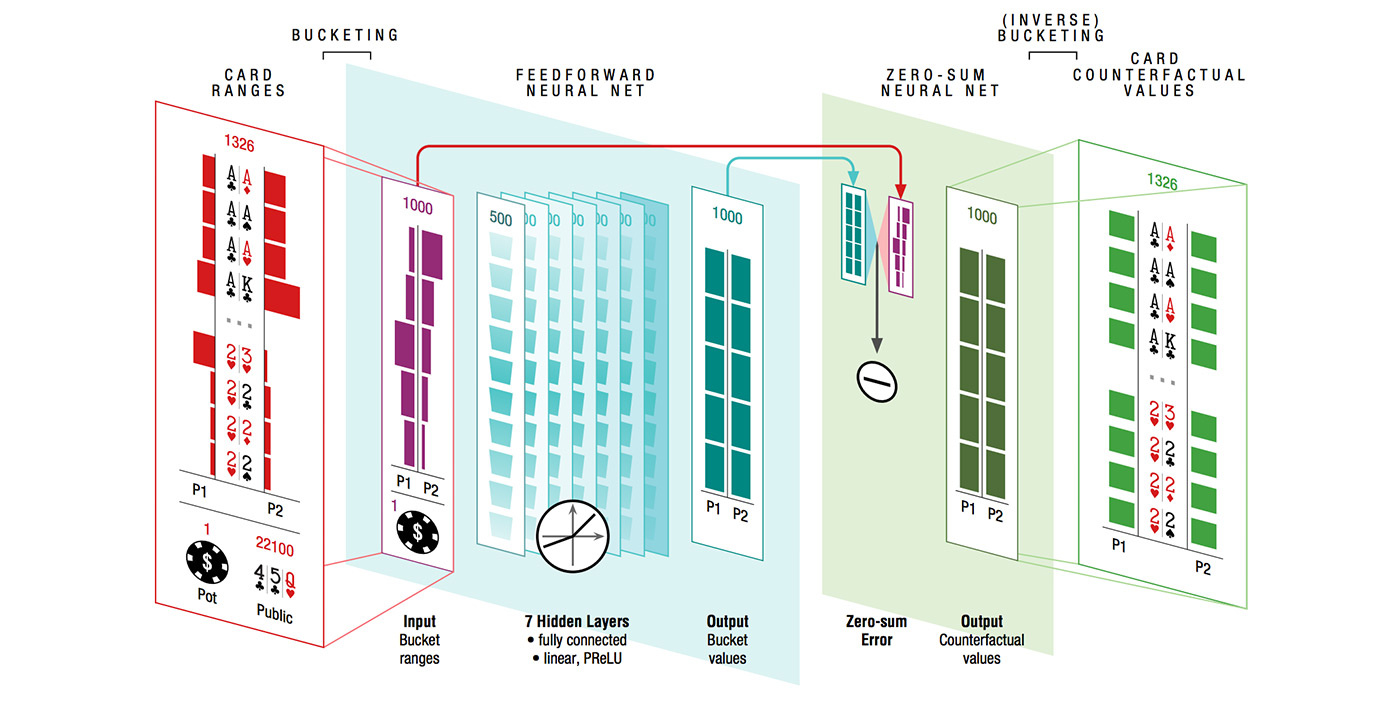
Архітектура нейронної мережі Deepstack
Зокрема, вище представлена архітектура нейронної мережі, використаної в алгоритмі DeepStack, про який ми писали в самому початку. На вхід мережі передаються дані про розмір ставок, розкритих картах і інформація про гравців, після чого їх дані перетворюються в вистава «кластерів карткових рук». Ця інформація подається на вхід 7-шарової нейронної мережі, після чого її результат додатково пост-обробляється для задоволення теоретико-ігровим критеріям нульової суми. Подробиці про DeepStack доступні в статті Університету Альберти .
Як ми можемо бачити, простір для можливих рішень однієї з найскладніших для ІІ ігор на сьогоднішній день величезний. Учасники Sberbank Holdem Challenge вільні використовувати будь-який підхід або їх комбінацію, що приводить їх бота до перемоги.
Робоча платформа для вирішення онлайн-етапу розміщена на holdem.sberbank.ai . На ній ви знайдете всі необхідні матеріали, а також зможете зареєструвати і відправляти свої рішення для онлайн-етапу.
Ми не очікуємо понад-людських результатів рішень на онлайн етапі, так як розуміємо, що на таку складну задачу потрібно багато часу. Однак, під час онлайн-етапу можна навчитися писати власних покерних ботів, розібратися з платформою і форматом рішень.
І звичайно, приклавши трохи зусиль, можна потрапити на оффлайн-етап змагання - базовий приклад бота все ще в топ-100 :)
До кінця онлайн-етапу залишилося менше двох тижнів - поспішайте!
Корисні посиланняАле як справи з іграми з неповною інформацією?
