






Наша взаимовыгодная связь https://banwar.org/
IT Manager Безпека управління ІБ Олексій Лукацький
| 31.10.2018

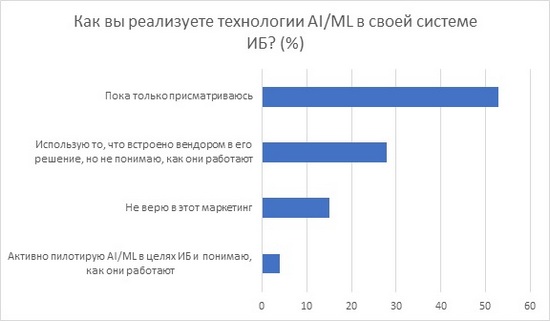
На IDC Security Roadshow 2018 мені довелося провести опитування серед фахівців з кібербезпеки і запитати їх про те, звертаються вони у своїй діяльності до штучного інтелекту або, якщо бути більш конкретним, до машинного навчання. Цікаво, що приблизно схоже розподіл, за даними Gartner, існує і щодо інших сфер застосування штучного інтелекту (ІІ), що показує певну недовіру до цієї технології або нерозуміння дарованих нею переваг. У статті мені хотілося б подивитися на те, як може використовуватися ІІ і машинне навчання в кібербезпеки.
традиційна кібербезпека
На жаль, треба визнати, що сьогодні безпеку в масі своїй реактивна. Ми боремося з тим, що вже когось зачепило, заразила, вивело з ладу, вкрав гроші. І ефективність системи захисту залежить від того, наскільки швидко ми будемо дізнаватися про атаки, з якими хтось вже зіткнувся.
Ви знаєте адресу домену «kill switch», який перевірявся гучної шкідливою програмою WannaCry і в разі його відсутності заражав комп'ютер? Це iuqerfsodp9ifjaposdfjhgosurijfaewrwergwea [.] Com, і інформацію ви отримали від компаній, які змогли дослідити дану атаку і своєчасно надати вам відповідну інформацію. А коли стало відомо про шкідливу програму Olympic Destroyer, що атакувала інфраструктуру зимових Олімпійських ігор в Південній Кореї, то боротися з нею вам дозволило знання відповідного хеша (сигнатури) db1ff2521fb4bf748111f92786d260d40407a2e8463dcd24bb09f908ee13eb9. А тепер ускладнити приклад. Існує такий вірус-шифрувальник Locky, який заражав в день близько 90 тисяч жертв, вимагаючи з них викуп за повернення доступу до файлів в розмірі 0,5-1 біткойнов. Один з доменів, звідки поширювався Locky, був * .7asel7 [.] Top. Якщо ми внесемо його в чорні списки, то чи можна бути впевненим, що ми захистилися від цієї загрози? На жаль. Зазначений домен був асоційований з IP-адресою 185.101.218.206, на якому, в свою чергу, «висіло» ще близько 1000 шкідливих доменів, наприклад, ccerberhhyed5frqa [.] 8211fr [.] Top і інші. Найнеприємніше, що такі домени можуть створюватися тисячами і використовуватися не більше одного-двох разів. Як захиститися від них? Вносити до чорного списку? Вони будуть розпухати з неймовірною швидкістю. До речі, та ж проблема і у антивірусів або систем виявлення атак, що використовують в основі сигнатурні методи виявлення. У сучасних антивірусів величезні бази сигнатур, що налічують мільярди записів. При цьому щодня виявляється більше мільйона шкідливих програм, і в багатьох атаках використовуються унікальні шкідливі програми, з якими раніше ніхто не стикався.
Що таке машинне навчання
На відміну від традиційних методів виявлення чогось поганого, що спираються на боротьбу з чимось знайомим, машинне навчання дозволяє нам пізнати б тоді, що ще невідомо. Щоб зробити це, на вхід моделі / алгоритму необхідно подати вхідні дані (багато даних), на яких модель буде навчатися. Після навчання моделі можна подавати на вхід нові дані, і вона почне виявляти в них шукане.
Машинне навчання базується на трьох ключових елементах:
Датасета. Щоб навчити модель розпізнавати щось (поганий або хороший), їй на вхід треба подати великі обсяги даних, які називаються датасета. Це може бути інтернет-трафік, мережеві потоки, логи, поштові повідомлення, активність користувача і багато іншого. Чим більше і різноманітніше навчальні дані, тим точніше буде результат передбачення. Щоб навчитися визначати спам, нам потрібні сотні тисяч і мільйони електронних повідомлень для аналізу. Щоб навчитися передбачати поведінку користувача, потрібно відстежувати всі його дії протягом кількох тижнів. Щоб виявляти шкідливі домени, треба вивчати сотні мільярдів і трильйони DNS-запитів. Від якості датасета залежить ефективність машинного навчання - якщо даних мало, вони неповні або неякісні (а то і зовсім в них можуть бути спеціально внесені некоректні дані), то ніяка, навіть найкраща модель машинного навчання допомогти буде не в змозі.
Ознаки. Це те, що ми шукаємо в датасета. Наприклад, доменне ім'я, відправник e-mail, IP-адреc, тривалість мережевий сесії, використовуваний протокол, час дня і т. Д. В залежності від розв'язуваної задачі можуть бути сотні різних ознак. Наприклад, у деяких систем захисту кінцевих пристроїв може бути понад 400 ознак - це метадані, асоційовані з аналізованих файлом: ім'я, дата створення, розмір, наявність мережевих підключень, нестандартні протоколи, використання певних викликів, внесення змін в файлову систему, розробка під певну архітектуру , звернення до реєстру і т. д.
Алгоритми / моделі. Знайти за певними ознаками шукане в датасета можна різними способами, вибір яких залежить від безлічі параметрів. Правильний вибір алгоритму або моделі - це завжди баланс між швидкістю роботи, акуратністю передбачення і складністю моделі. А тому зазвичай на практиці експериментують з моделями, вибираючи з них найбільш підходящу для конкретного завдання.
Види машинного навчання
Не існує універсального алгоритму машинного навчання (хоча кажуть, що нейросеть може претендувати на це звання, але навіть типів нейромереж існує два десятка) - різні моделі застосовуються для різних завдань. Їх прийнято класифікувати або за типом навчання, або по функції, наприклад:
за типом навчання:
по функції:
регресія,
дерева рішень,
байєсовські,
кластеризація,
нейромережі.
Алгоритми класичного машинного навчання (з учителем або без нього) використовуються в тих випадках, коли у вас прості дані і зрозумілі ознаки. Наприклад, блокування платіжної картки після зняття готівки за кордоном. Тут все просто. Зазвичай всі ваші транзакції проходять в домашньому регіоні, а тут аномалія - раптове (якщо ви не попередили заздалегідь свій банк про поїздку) зняття готівки за межами країни. Напевно, до 50% всіх алгоритмів машинного навчання, які використовуються в тому числі і в ІБ, - вічна класика. З її допомогою можна швидко вирішити потрібну задачу.
До 75% всіх класичних алгоритмів - навчання з учителем, тобто робота з вже розміченими або маркованими даними. Наприклад, моделі треба сказати: це спам, а це немає; це DDoS, а це немає; це шахрайство (фрод), а це немає. За допомогою навчання з учителем ви зможете легко класифікувати нові дані, виявляючи в них щось аномальне. За допомогою таких алгоритмів можна виявляти завантаження раніше невідомого шкідливого коду, спам- і фішингові атаки, DGA-домени (автоматично створювані шкідливі домени), комунікації з командними серверами і ботнетами. Найпопулярнішими алгоритмами з учителем можна назвати класифікацію і регресію. Класифікація дозволяє передбачити категорію, а регресія - передбачити значення. І якщо вам потрібно передбачити, коли у вас буде зростання атак, то вам потрібна регресія, а якщо ви хочете зрозуміти, яких атак у вас буде більше через півроку, знадобиться класифікація. Кожен з обох типів може поділятися на підмножини алгоритмів машинного навчання з учителем. Скажімо, до класифікації відносяться дерева рішень, random forest або SVM. З їх допомогою можна детектувати, зокрема, атаки SQL Injection або підозрілий HTTP-трафік.
Але що робити, коли вхідні дані не розмічені? Уявімо собі, що наша система захисту фіксує чотири невдалих спроби входу під одним обліковим записом. Це явне порушення, оскільки у нас в політиці передбачено обмеження в три спроби. Для виявлення чотирьох і більше невдалих спроб не потрібно машинне навчання. Активність одного облікового запису з різних географічних точок протягом однієї доби може означати шкідливу активність. А може і ні, якщо ви, наприклад, полетіли у відрядження і заходили в захищається систему, скажімо, з аеропортів Москви, Лондона, Нью-Йорка і Чикаго. Такі сценарії банки часто вважають шахрайством, блокуючи відповідні карткові транзакції. Для виявлення подібної активності також не потрібно машинне навчання. А ось для доступу з незвичного місця вже знадобиться. Тому що ми заздалегідь не знаємо, яке місце є звичним, а яке - ні. Тут і допоможе навчання без вчителя і один з його алгоритмів - кластеризація, яка дозволяє об'єднувати схожі події кластери. Поява нестандартного місця входу (не потрапляли в кластери) є аномалією і може служити сигналом крадіжки облікового запису. Даний підхід буває менш точний, ніж навчання з учителем. Так, у вищенаведеному випадку може виявитися, що це навіть не крадіжка облікового запису, а користувач дав добро якомусь з додатком через OAuth підключатися до захищається (зокрема, до хмарного сховища) і благополучно забув про це.
Інший сценарій, де добре спрацьовує навчання без учителя, - виявлення витоків інформації або саботаж адміністратора. Ви не можете сказати, де провести межу між нормальним і аномальним числом видаляються з хмари або скачуваних по локальній мережі на один комп'ютер файлів. У вас є можливість тільки порівнювати між собою ця ознака у різних користувачів і груп користувачів, об'єднуючи їх в кластери і виявляючи тим самим нормальне і аномальне поводження. Припустимо, зазвичай користувачі в день вивантажують в Інтернет близько 100 Мбіт даних, але в один з днів, якийсь користувач викачав більше 10 Гбіт. Це явна аномалія, яка визначається і без машинного навчання. Однак машинне навчання нам допоможе об'єднати декілька ознак (наприклад, обсяг даних, час, протокол, тип даних, адреса одержувача) і відокремити вивантаження дистрибутива нової версії додатка для віддалених офісів від крадіжки даних.
Нейросети - це теж один з видів алгоритмів машинного навчання без учителя, які останнім часом набувають все більшої популярності. Зазвичай вони застосовуються там, де досить складні датасета (зображення осіб в біометрії, а також голос або зображення документів) або важко виділити ознаки, які будуть вибирати модель в датасета. Ключова ідея нейромережі - можливість внутрішнім її верствам робити власні судження про те, що важливо в датасета і що повинно бути вилучено з нього в процесі навчання. Всі вищеописані приклади можуть бути виявлені нейросетями, але зазвичай їх використовують в більш складних сценаріях - розпізнавання фальшивих документів, боротьба з погрозами для біометрії, пошук витоків інформації в голосових комунікаціях, розпізнавання текстів з безпеки і т. П. Одним із серйозних недоліків нейромереж можна назвати відсутність зворотного зв'язку, тобто неможливість пояснити, чому з вхідних даних вийшов саме такий результат.
висновок
Сучасна інформаційна безпека стикається з низкою труднощів, серед яких слід назвати величезні потоки подій, зниження експертизи і брак персоналу. При цьому число атак зростає, незважаючи на вжиті заходи захисту. В даний час середній період невиявлення загроз становить близько 200 днів, що стає результатом реактивності використовуваних захисних засобів. Тому сьогодні, як ніколи, важливо застосовувати нові методи боротьби зі шкідливою активністю, найперспективнішим з яких представляється машинне навчання.
Так, поки ми не досягли того рівня, щоб повністю відмовитися від участі людини в прийнятті рішень в області кібербезпеки. Абсолютна більшість розроблених сьогодні моделей дозволяє нам детектувати нові загрози, аномалії і підозрілі дії, відповідаючи на питання «що сталося?» І «чому це сталося?». Поки ми майже не вміємо пророкувати майбутнє в ІБ (виключаючи деякі вузькі сфери), а тому питання «що трапиться?» Залишається без відповіді. І вже тим більше ми не знаємо, як відповісти на питання «що я повинен зробити?» (До якої аналітика, яка є долею майбутнього).

За останні шість років на ринку кібербезпеки було зафіксовано понад 220 поглинань, пов'язаних зі штучним інтелектом. Цей напрямок зараз входить до п'ятірки найбільш поширених угод, а багато гравців (виключаючи, мабуть, вітчизняних) ринку ІБ активно інвестують в технології машинного навчання, інтегровані в свої продукти. Але кінцевий споживач в масі своїй поки не може активно скористатися всіма перевагами штучного інтелекту - у нього немає для цього ні правильно оброблених датасета, ні, що найважливіше, кваліфікованих аналітиків даних, здатних самостійно розробити або застосувати існуючі моделі аналізу. Однак навіть для того, щоб користуватися моделями машинного навчання в придбаних або експлуатованих рішеннях, необхідно розуміти, що являє собою дана технологія.
Однак слід пам'ятати, що машинне навчання не панацея. По-перше, існує цілий клас атак на нього, спрямованих як на датасета, так і на самі алгоритми, що може привести до невірних рішень, пропущеним атакам або помилкових спрацьовувань. А по-друге, зловмисники теж починають застосовувати методи машинного навчання в своїй кримінальній діяльності - створення шкідливих програм, аналізі поведінки користувачів, розробці ботів-складальників персональних даних, пошуку вразливостей, фішингу, підборі паролів, підміні особистості, обході систем захисту і т. П . І протиставити таким зловмисникам можна тільки штучний інтелект. Тому застосування машинного навчання в інформаційній безпеці - необхідність, без якої сучасну систему кібербезпеки уявити неможливо.
Ключові слова: штучний інтелект , безпеку
Гарячі теми: Загрози і ризики ІБ
Журнал IT-Manager № 10/2018 [ PDF ] [ Підписка на журнал ]
про авторів
Олексій Лукацький
Бізнес-консультант з безпеки Cisco. В області інформаційної безпеки з 1992 року. Автор понад 600 друкованих праць. Нагороди Асоціації документального електрозв'язку «За розвиток інфокомунікацій в Росії», Інфофорума в номінації «Публікація року», Security Awards за просвітницьку діяльність та інші. У 2013-му і 2014-му роках порталом DLP-Expert був названий кращим спікером з інформаційної безпеки. Автор курсів «Вступ до виявлення атак», «Системи виявлення атак», «Як пов'язати безпеку з бізнес-стратегією підприємства», «Що приховує законодавство про персональні дані», «ІБ і теорія організації», «Вимірювання ефективності ІБ», «Архітектура і стратегія ІБ »і др.Участнік технічного комітету 362« Захист інформації »Федерального агентства з технічного регулювання і метрології та ФСТЕК. Учасник робочої групи Ради Федерації по розробці поправок до ФЗ-152 і розробці Стратегії кібербезпеки Россіі.Участнік робочої групи Ради Безпеки по розробці основ державної політики щодо формування культури інформаційної безпеки.
Ви знаєте адресу домену «kill switch», який перевірявся гучної шкідливою програмою WannaCry і в разі його відсутності заражав комп'ютер?Якщо ми внесемо його в чорні списки, то чи можна бути впевненим, що ми захистилися від цієї загрози?
Як захиститися від них?
Вносити до чорного списку?
Але що робити, коли вхідні дані не розмічені?
Абсолютна більшість розроблених сьогодні моделей дозволяє нам детектувати нові загрози, аномалії і підозрілі дії, відповідаючи на питання «що сталося?
» І «чому це сталося?
Поки ми майже не вміємо пророкувати майбутнє в ІБ (виключаючи деякі вузькі сфери), а тому питання «що трапиться?
І вже тим більше ми не знаємо, як відповісти на питання «що я повинен зробити?
